Pedestrian Flow Statistics
The basic idea of how to do Pedestrian Flow statistics Or we can call it Person Re-ID are similar to me last blog:Person ReIDMNIST
The steps are as follows:
- Use Simaese Network to extract the Feature Vector(128 dimension) of dataset
- Choose a group of test data and test them in the Network we trained,we set a threshold to distingish different class, if a image’s Feature Vector distance to all other groups’ distance is larger than the threshold, we classify it as a new class, else, group it into the class of cloest distance
We want to use Market1501 to train our model, but we find that though there are more than 10K images in the Market1501, there are more than 700 different class in it, meaning that there are 20 images in each class in average. The images in one same group are so small that from my point of view, I think it can not achieve high performance. So I want to use GAN-based data augmentation to augment image in each class for example expand images in each class to 100
GAN
Pedestrian Flow Statistics
3th Feb: Plan to tomorrow:
1.Use GAN to augment image in each class
2.Many classic network set the feature vector as 156 dimension, we set it to 128 before, we need to change network structure to better represent input images feature.
The result of first day: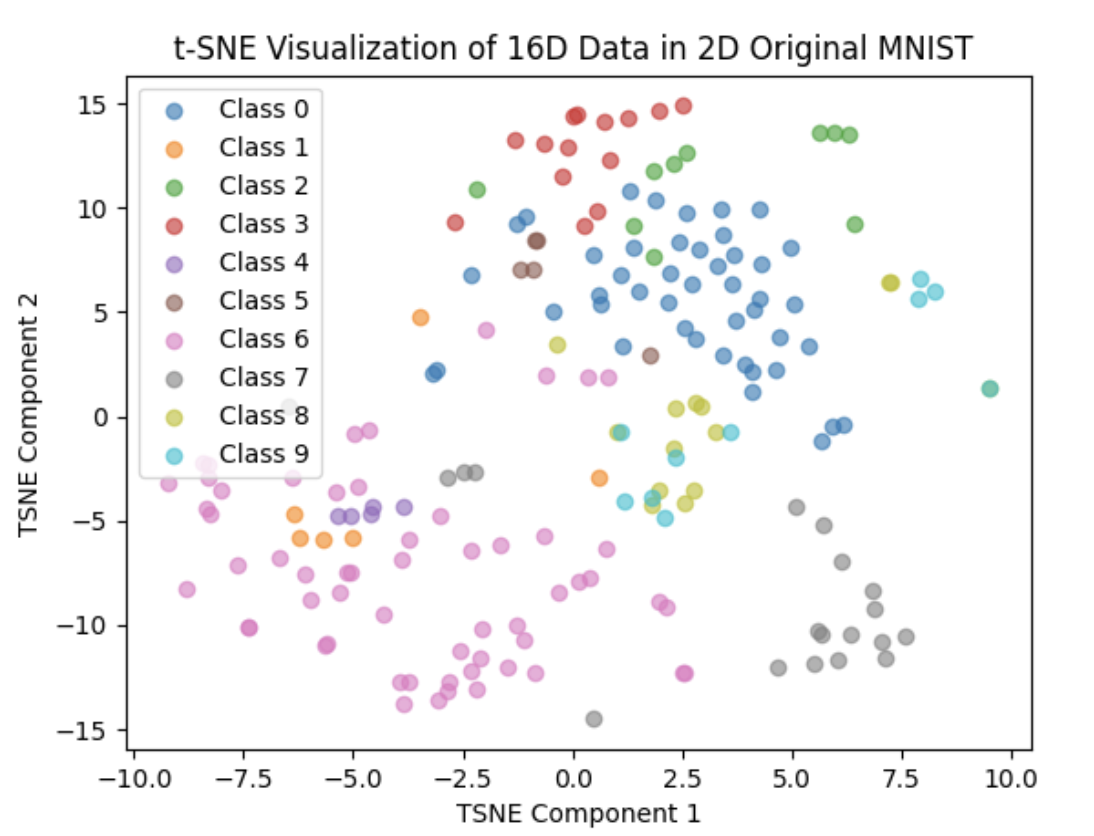
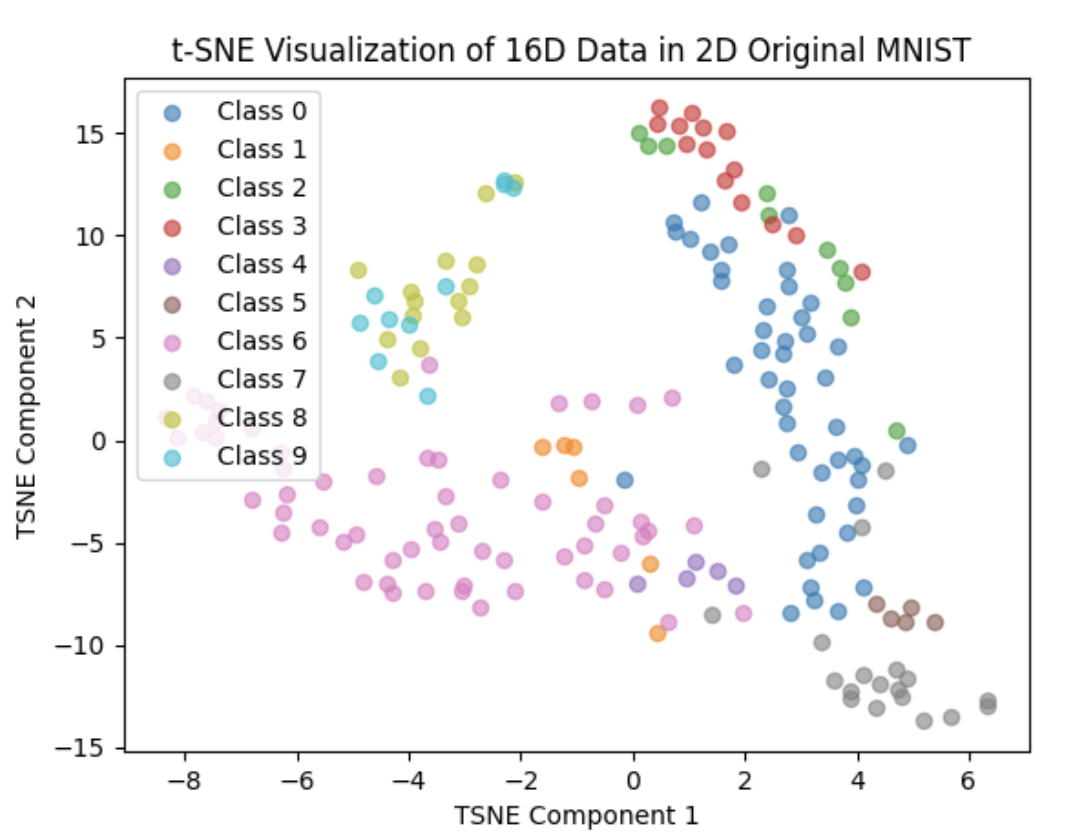
We modified our network into ResNet50 and set the dimension of feature vector output by the network to 1024 dimension, we trained 10 epochs and the result are as follows: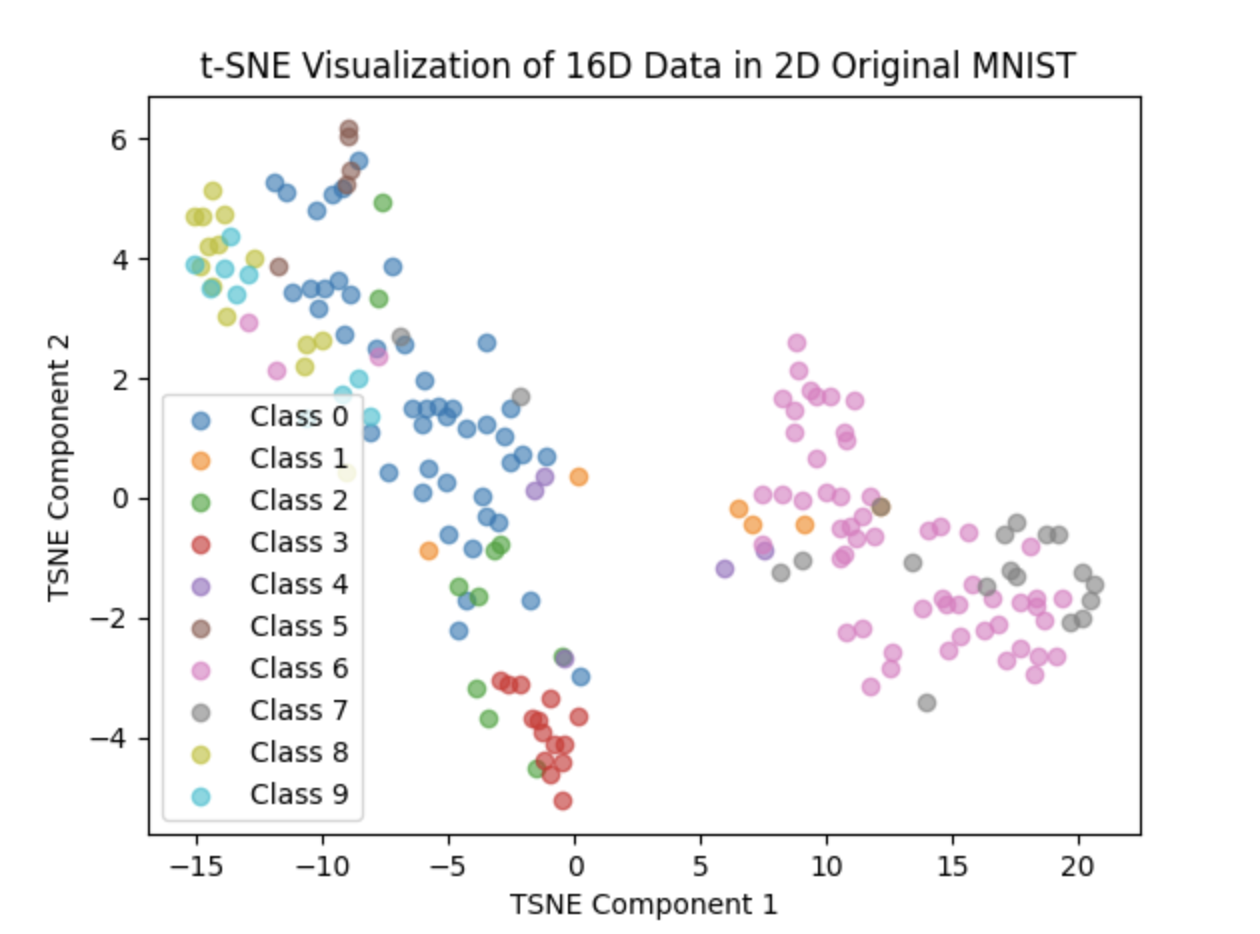
We find that during the training process, the GPU utilization are just 30% and memoryare just 1/8 so we want to correct code to accerlate the training process:
1.Optimize data loading
2.Enlarge batch_size
Batchsize will cause error in training process, we need to correct it
First: Before the batch size we set are only one, but here we set batch size to 64. Due to the lack of robustness, the triple loss function can not properly perform in this batch size. So we firstly change the triple loss function. At the same time,to perform triple dataset, we define a new class and doing the sampling in the class. And when we use it we change the transform parameter to achieve better training.
After the correcion of errors, we fount that during the training, the GPU utilization are really small in the begining and after some time, it will reach 100% just in a instant and drop to 0 later and the training blocks.
The reason for the above problem is that there are some data class which only has one picture in it. Since that Triplet loss need two different images from same class, so the program fall into a deadlock, we can add a if judgment and jump throught the class which only has one images or change the data folder, deleting the folder which only contain one image in it.
And the solution of the previous problem, run the train program and monitor the GPU usage, we will see:
We set num_workers = 10 when loading data and set batch_size = 8, because we think that there are no adequate data for we to train, if we set batch size too large, the number of updates of weight in the network will be very small, which will be bad.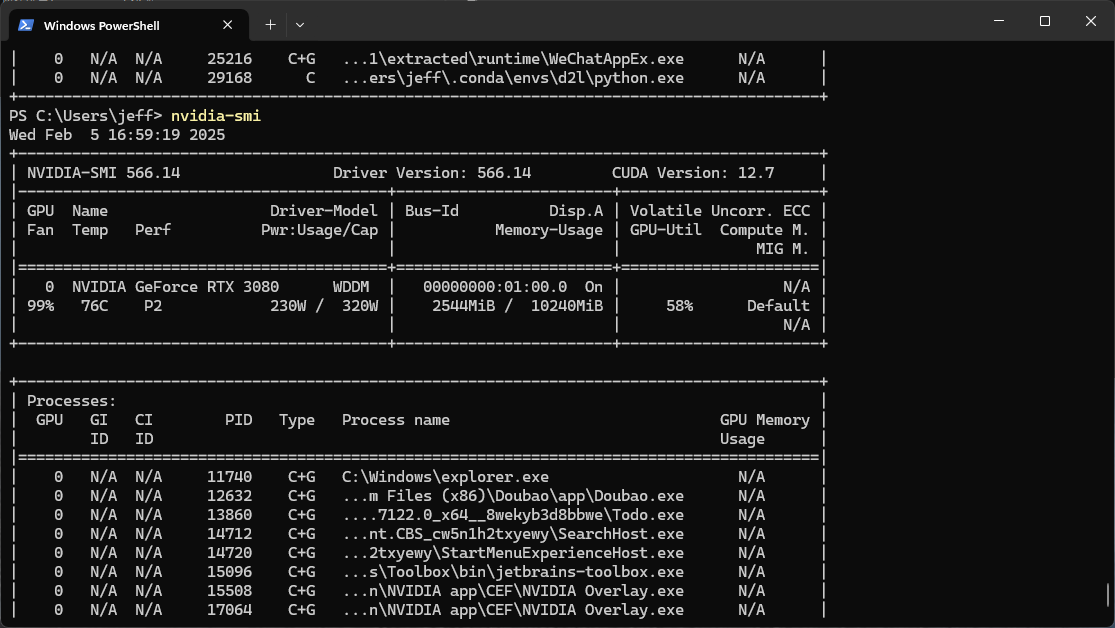
3.Use Mixed Precision Training(AMP)
4.Avoid the block between CPU and GPU
5.cuDNN Benchmarking
The 3,4 and 5 method we have not tried yet.
We trained our network in 50 epochs(with margin 0.9)but the result are not good as expected.
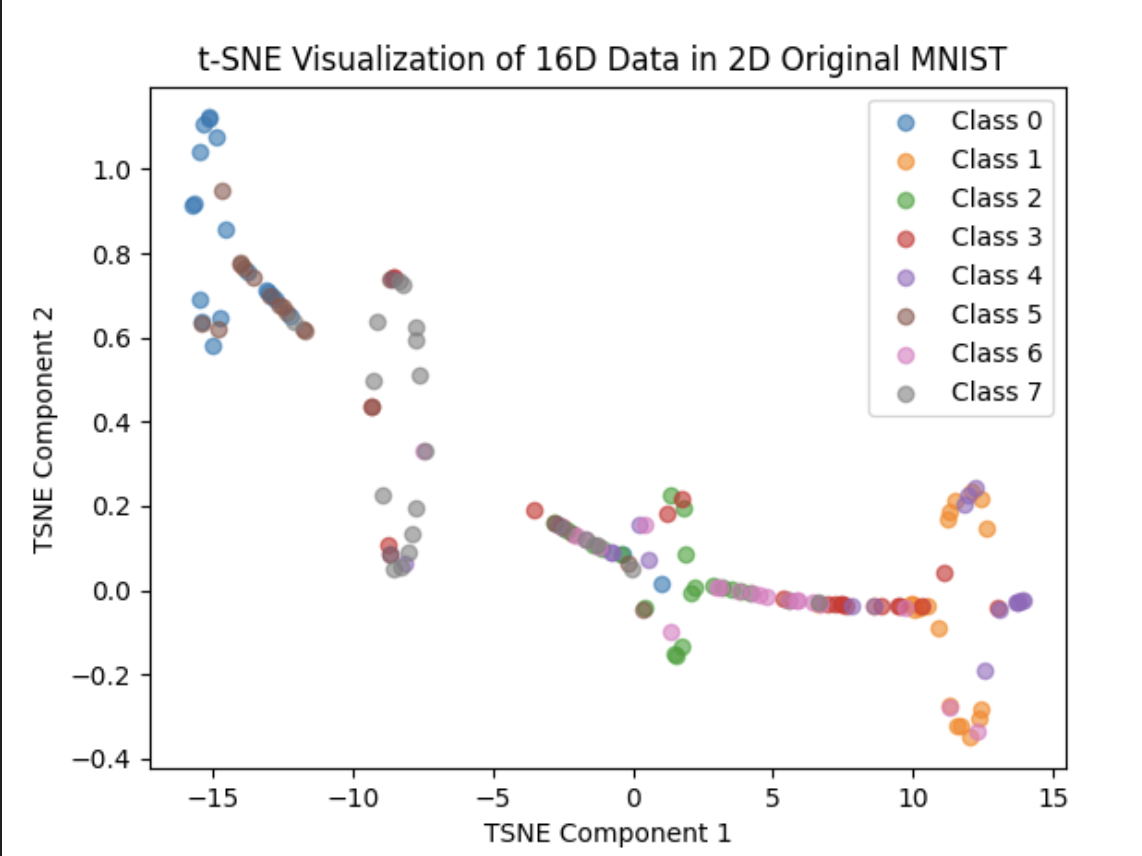
The T-SNE result are as follows: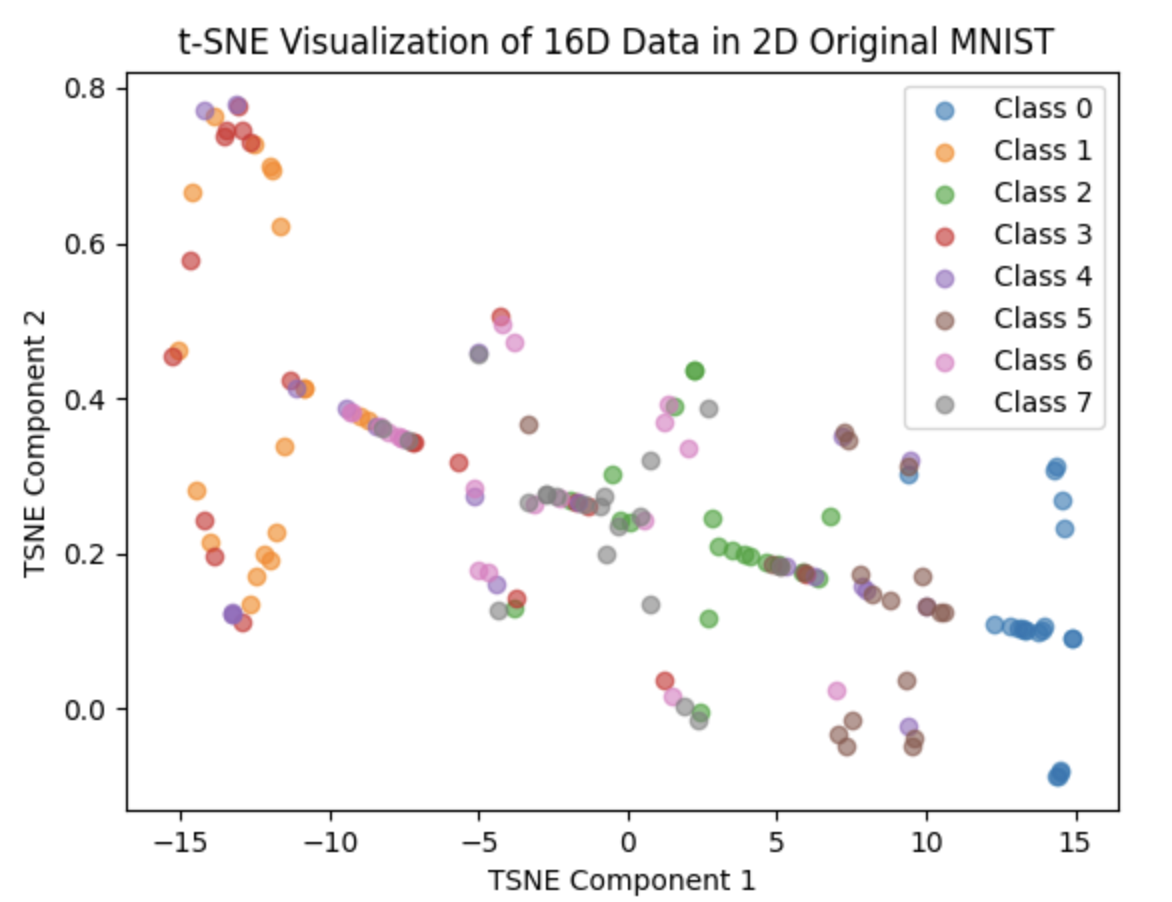
Then I made some adjustment regarding learning rate,margin,input image(RandomHorizontalFlip)loss, we set 32 as batch size and SGD each 4 data.
Learning rate:Cosine Annealing:
We use cosine annealing with warmup to adjust learning rate, the basic idea of cosine annealing are as follows:
Warmup Stage: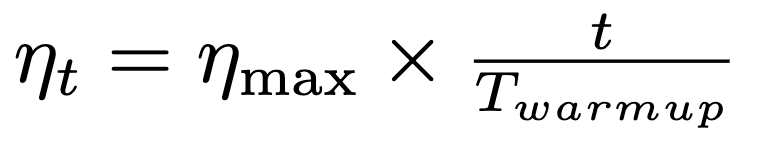
Cosine Annealing stage: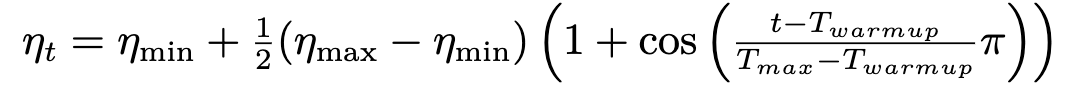
Where $/eta_t$ is the learning rate in current batch
$/eta_{max}$ is the preset max learning rate
$/eta_{min}$ is the preset min learning rate
$T_{warmup}$ is the warmup epoch we set before training
$t$ is current batch
$T_max$ is the total scheduling period (when the learning rate decays to the minimum value)
The plot of learning rate: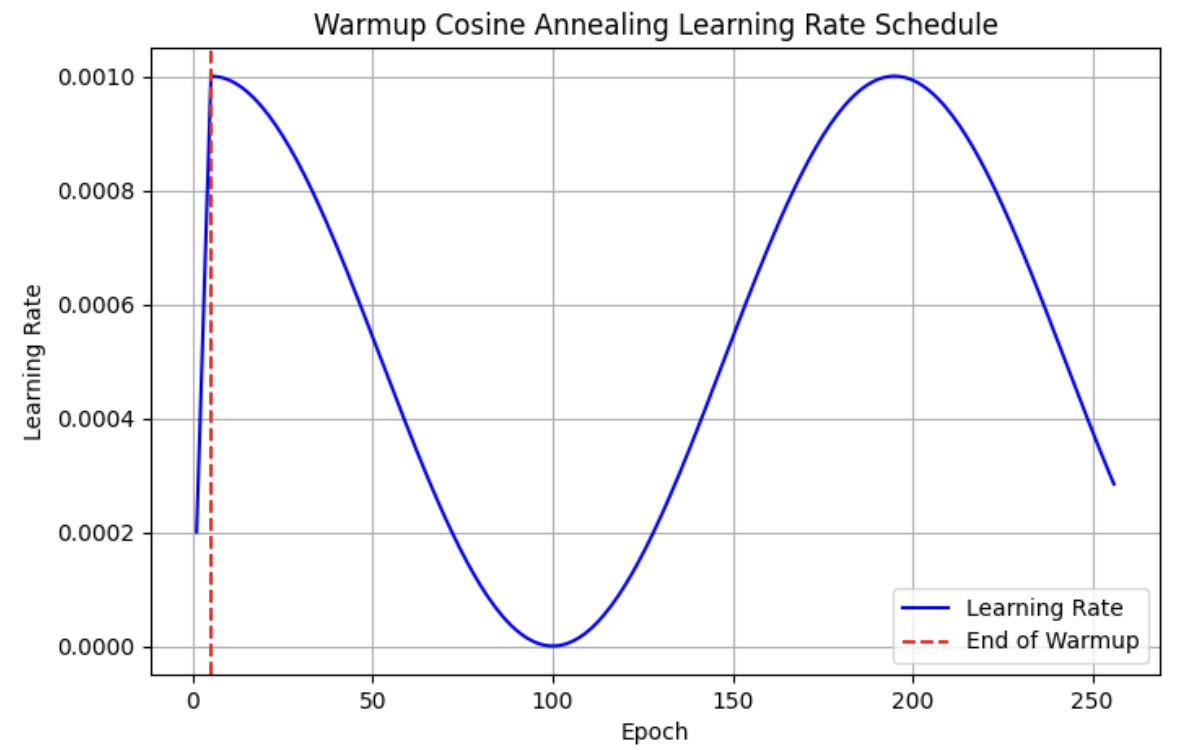
margin:0.3
RandomHorizontalFlip:random file the images a degree
We trained 20 epochs and the result are as follow: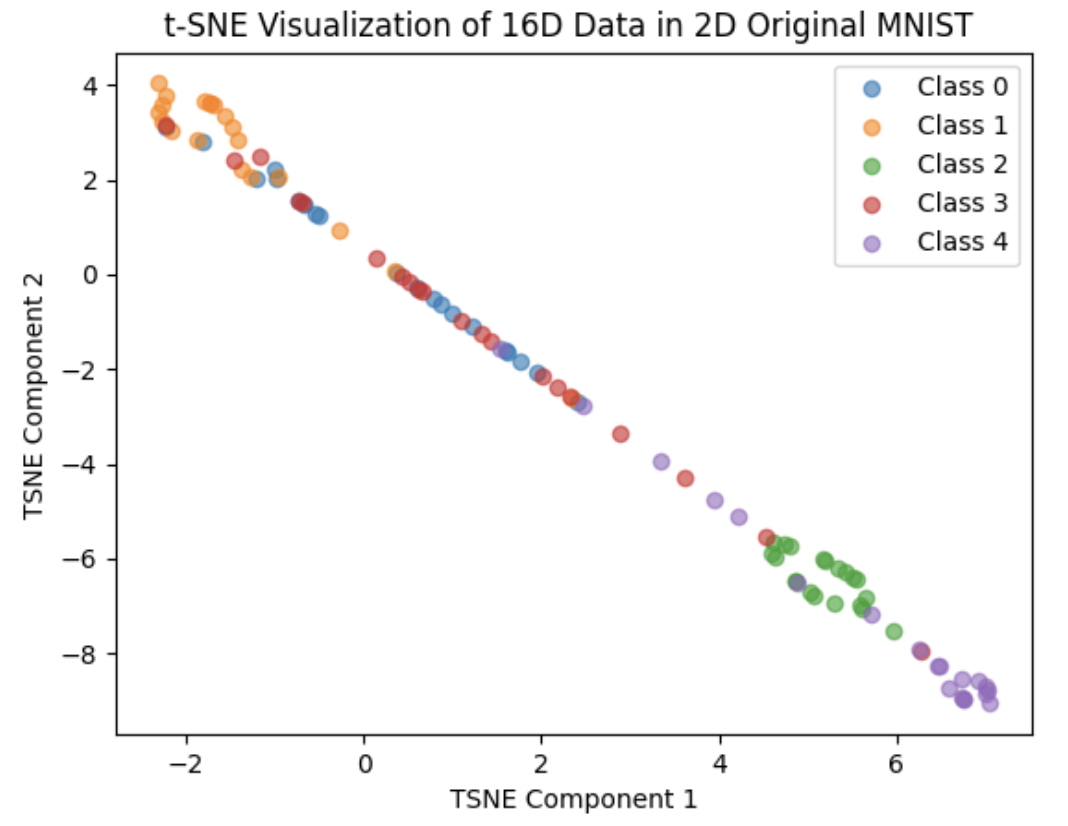
We can see that the result are not so good
6th Feb:
1.Adjust network structure
2.Adjust hyperparameters
3.Test GAN(But I think it is hard to to for it will cost a lot calculation resources)
We tried set batch_size large to accerlate calculation and SGD every 4 times, but we encounter some problems:
RuntimeError: Trying to backward through the graph a second time (or directly access saved tens) and RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [MPSFloatType [1024, 2048]] is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
We can simply understnad these problems as follows: Assume that we set batch size as 64 and we SGD every 4 times, thus, after the triplet loss call, we will have a 16-length loss list. Our original goal is SGD 16 times but the error message implys that after the first time SGD, the other loss are “out of date” and thus doing SGD on these loss are meaningless and even have some bad effect. That really make sense.
We find one huge problem in our training code: we find that when we calculate the cosine distance, we set the last parameter to 0 not -1 :
loss = torch.cosine_similarity(plot1, plot2,-1) This greatly influence the training process.
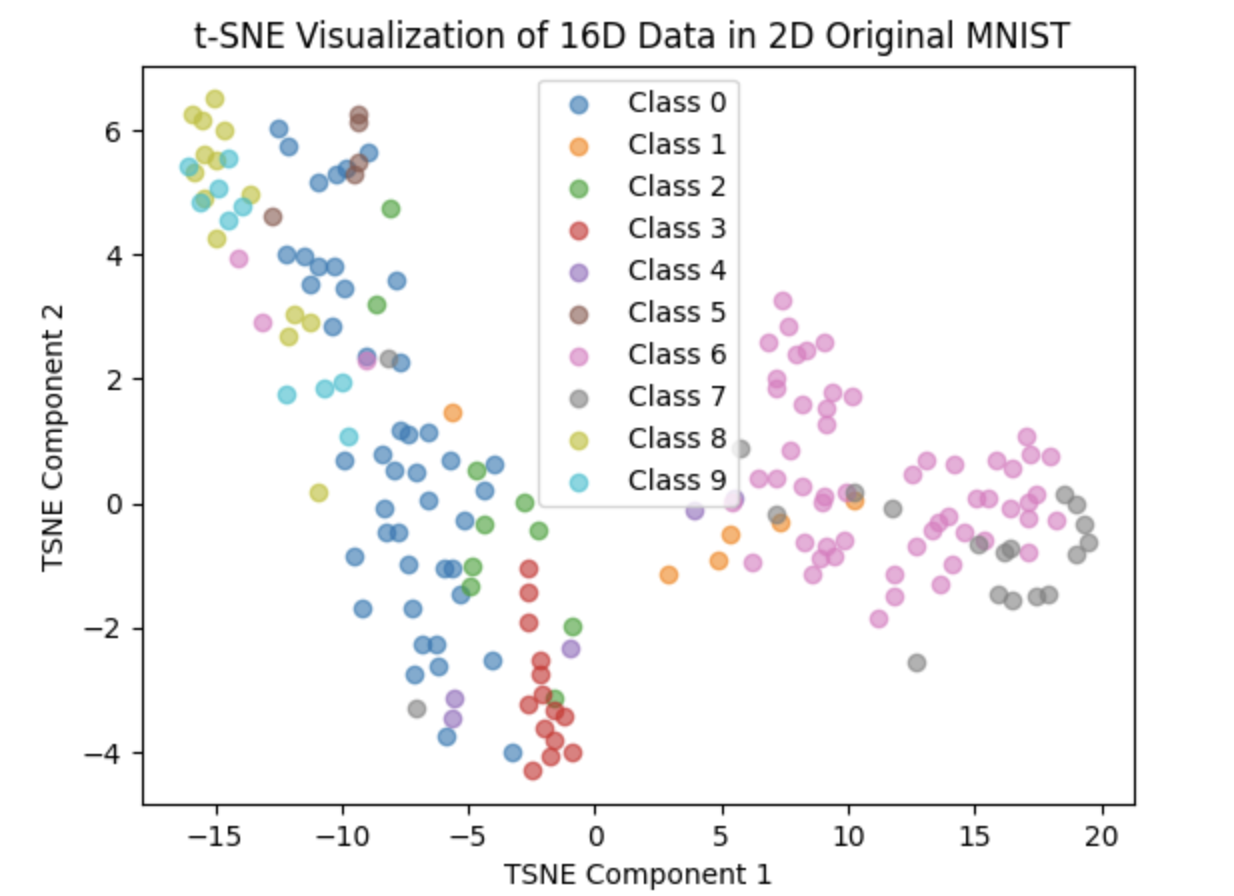
After the correction, we set the number of percton in last layer of the network to 256,512,1024,2048 and 4096, training each of them 20 epoch and the result are as follows:
256: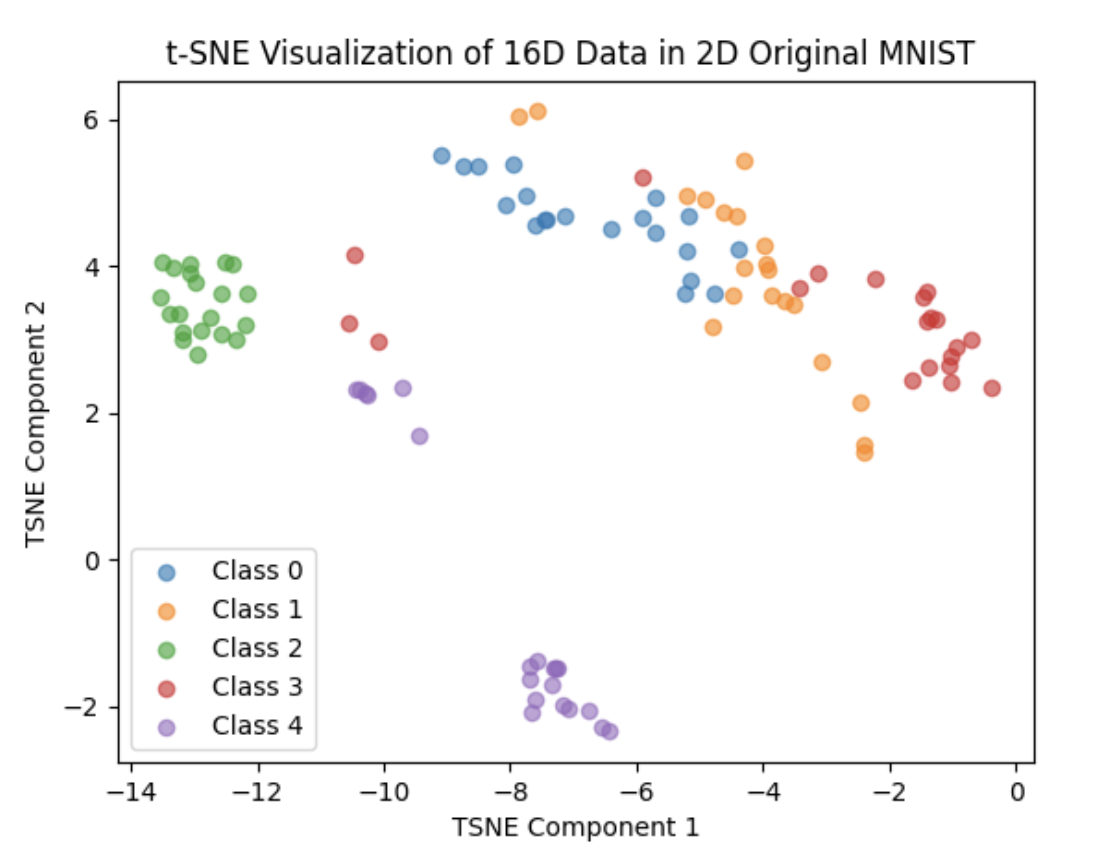
512: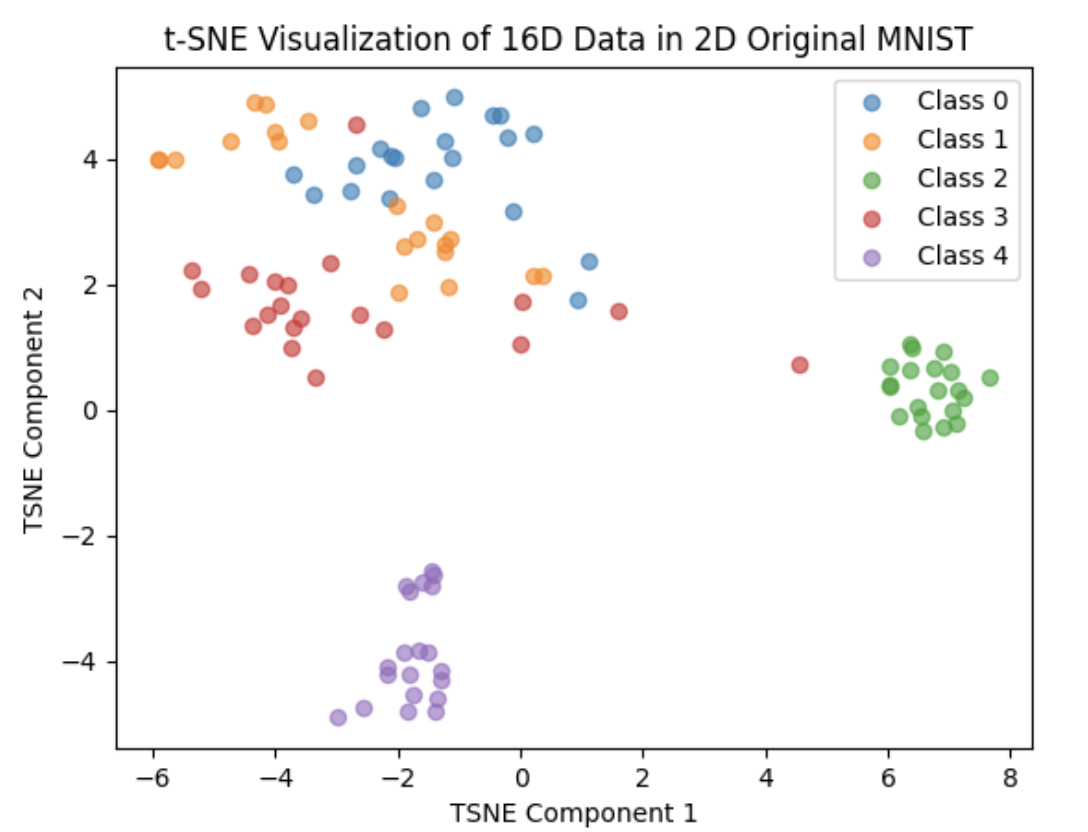
1024: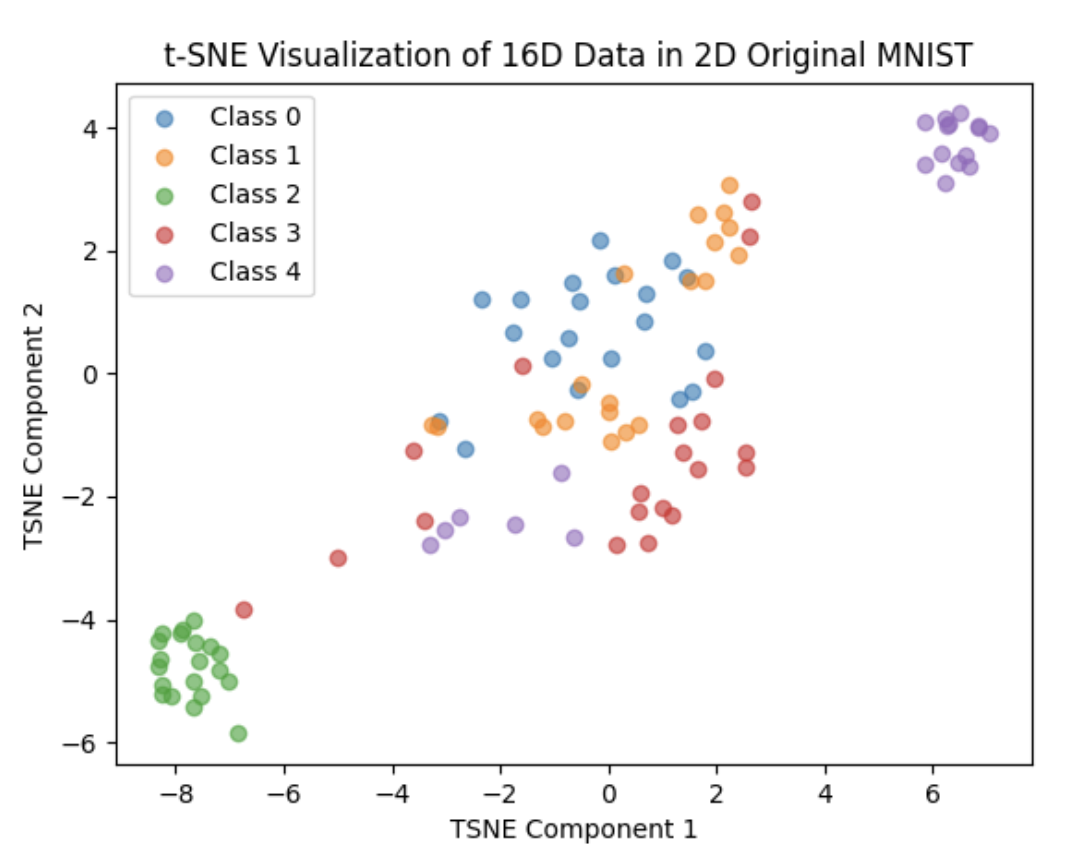
2048: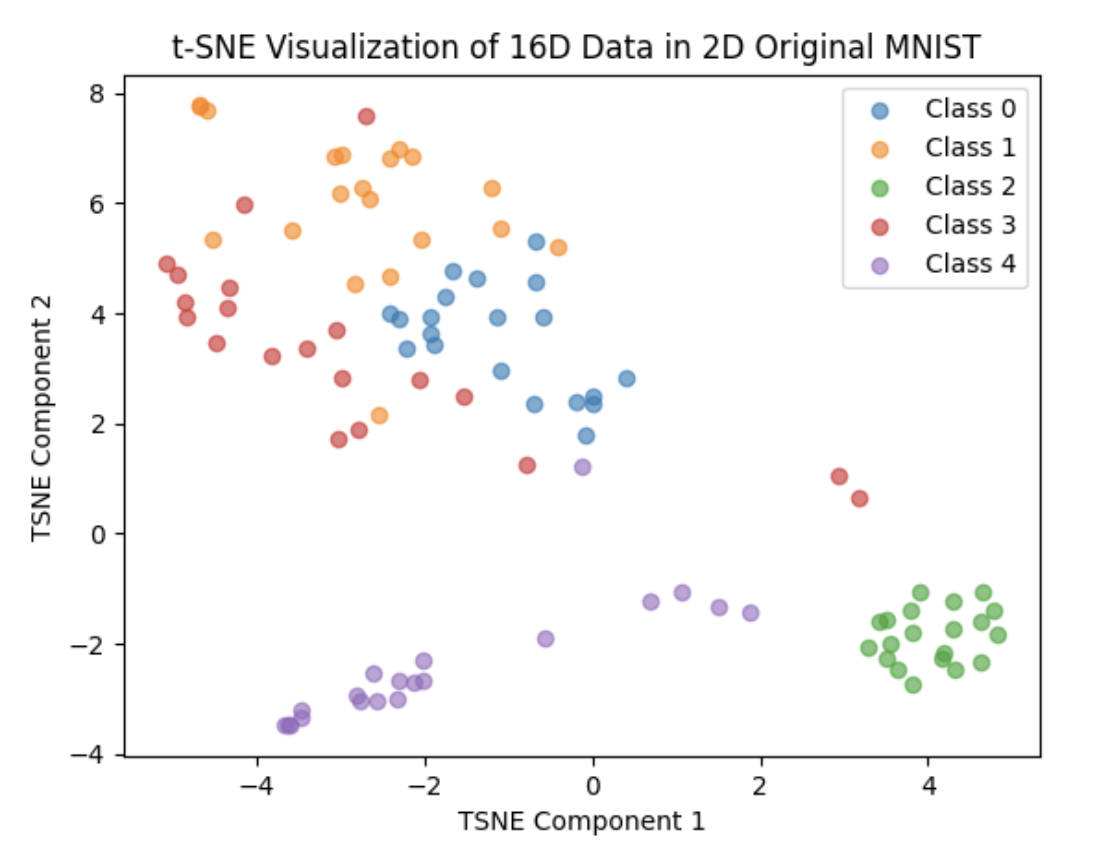
4096: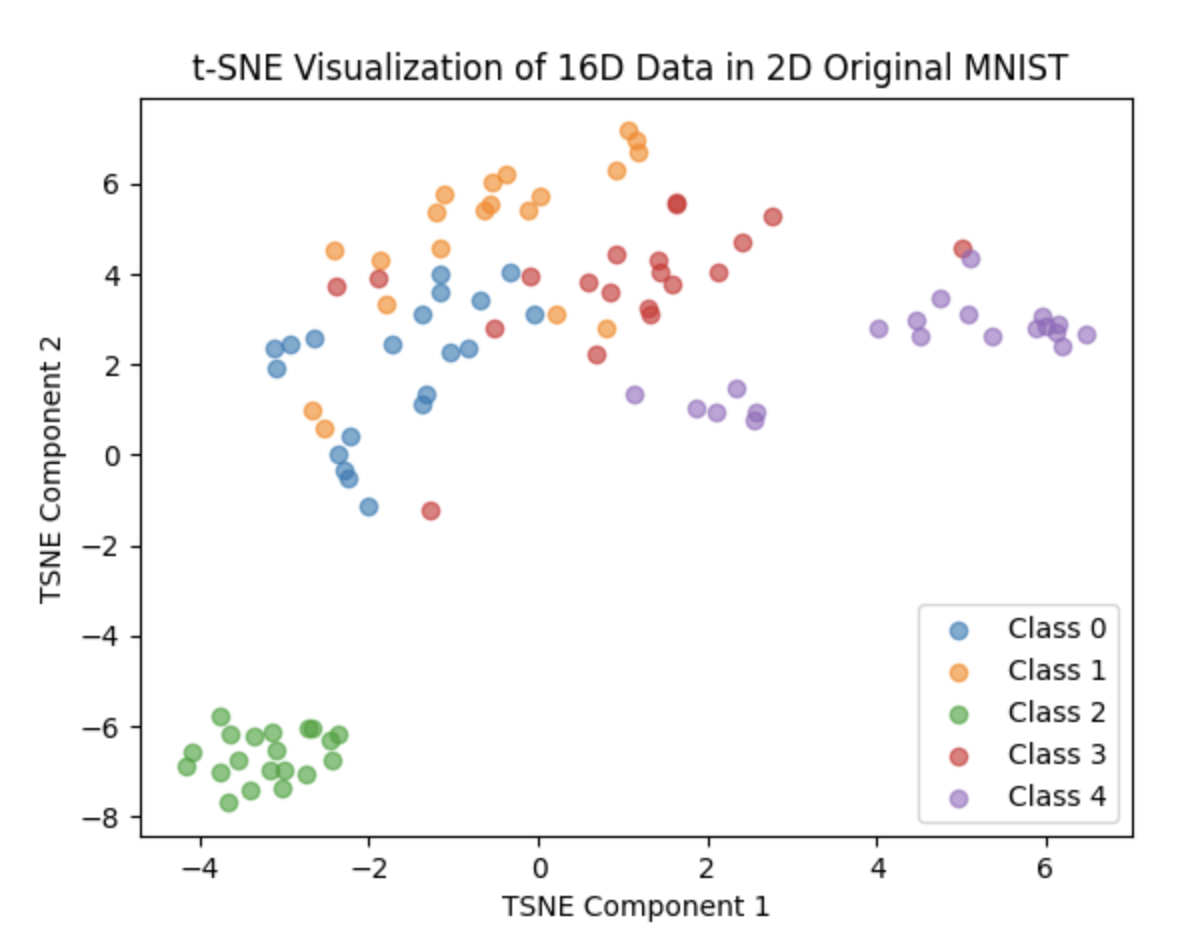
We can not clearly see the performance of the network in these 2D plots. So I do some statistic analysis on the distance in class and between class. We first calculate the top 50 in-class distance in each class(we have 5 classes in total)and compare each of them with other class distance(each point have 80 different class distance) Thus for each point, each top 505 in-class distance has 1600 different class comparison. The result are as follows:
256: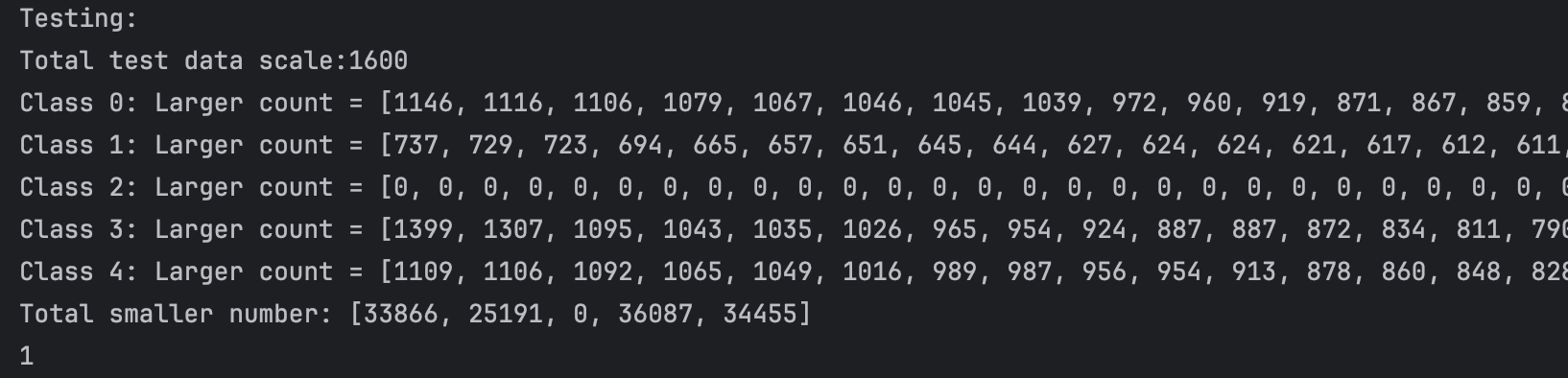
512: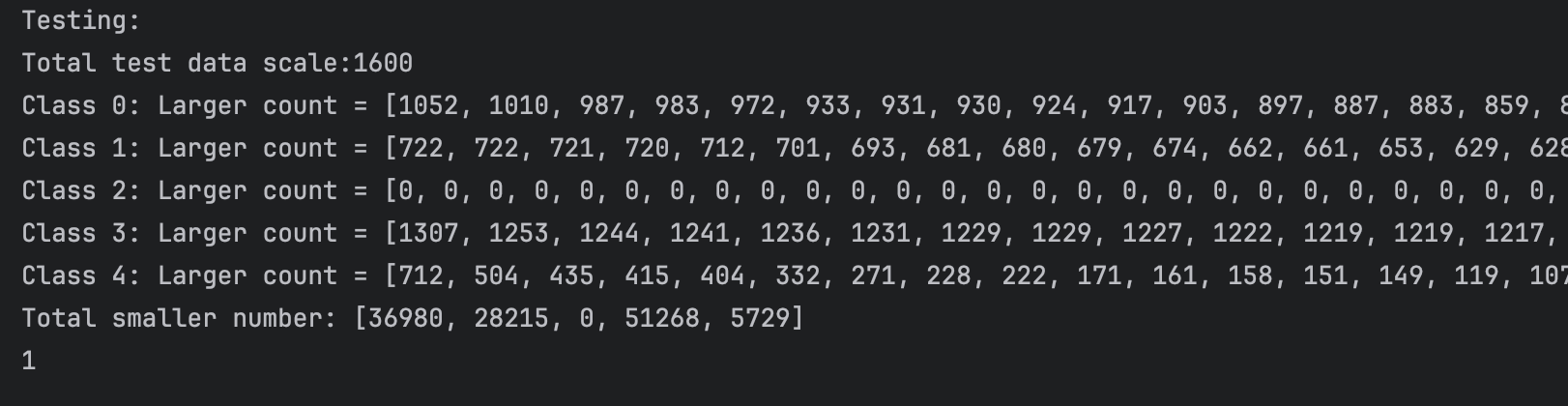
1024: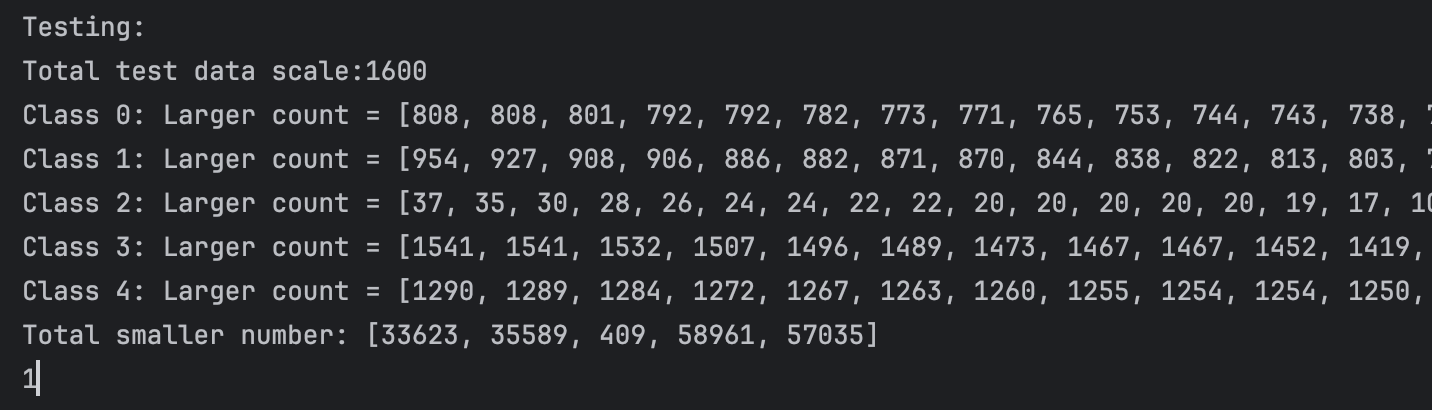
2048:
4096: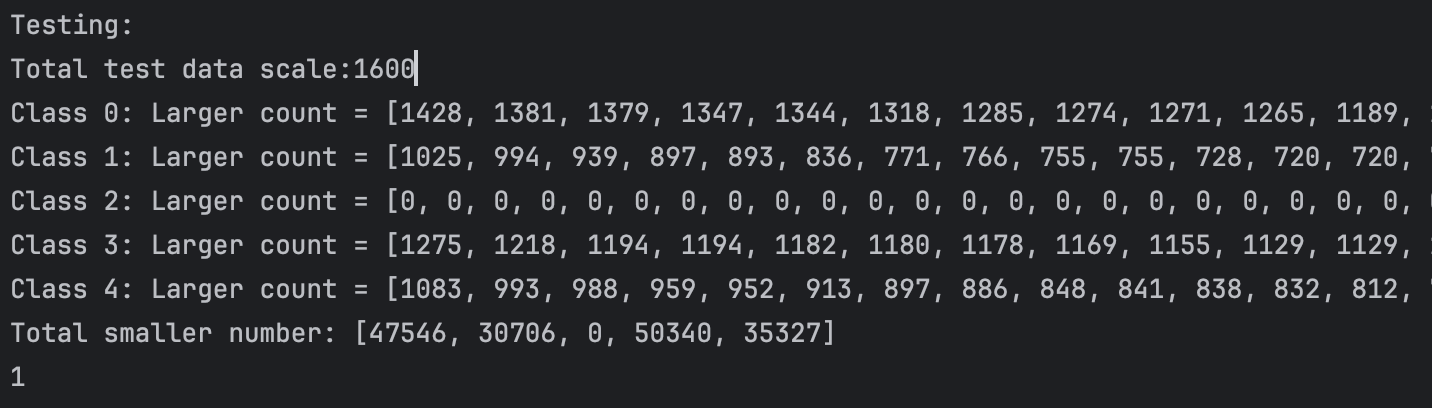
From the plot and test statistics we can see that 2048 perctons will have the best result. But the result are still not so good, did not reach our expectation. And at the same time, we also tried using random flipping to train, the result are just like without it, but it will cost more time in the dataloader stage and the result are even worse than without it.
I tried use online triplet mining for triplet loss. In theory, the result will be better. But what confused me a lot is that is we use online triplet mining, the loss will be 0, whatever the batch and epoch, to be more specific, all the parameters in the network are 0.0. I am very confused about it.
We find the reason for the problem is that if we set the dataLoader’s parameter workers_num > 0, the net weigth will all be 0 and if we set it to workers_num to 0, the speed accerlated a lot and the peoblem solved. We do not know the reason for this. I guess I know the reason for why it acaerlates a lot. One reason is that it cost a lot of time to fork and terminate the process.
TODO: Dataloader mechanism, The reason why the net weight will all be 0 if we set the dataloader’s parameter workers_num > 0
If we set the workers_num to 0, the data loading process will be very fast, but the training process will be realtively very slow. If we set workers_num to 10 the training process will be nearly 7 items per second, but if we set the workers_num to 0, the training process will be 1.7 items per second. So we still choose set workers_num to 10.
And this will cause a problem, just as before: Since we need network to calculate the embeddings of anchor image, positive image and negative image and do online triplet mining during the data loader process, if we set net as a parameter passed to the TripletDataset, the problem still exists: the net weight becomes all 0. There are two solutions for this: First, set workers_num to 0, this is not a good solution. Second, set net as a global variable and do not still set workers_num > 0. The second method will maintain the effciency of training. So we use the second method. However, we still encounter new problems: Since all the calculation and data are storged in GPU(We have a funciton .to(DEVICE) will causes that, if we do not use it, there is another porblem: The data and network have to on the same device), the storage of GPU is not enough for such a huge amount of data. And one thing we want to mention is that during the enumerate of train_dataset, the net are still at “train” mode, since we want the calculation in enumerate of train_dataset, we set the net to eval mode and and use torch.no_grad() and use “anchor_embedding = net(anchor_img.unsqueeze(0).to(DEVICE)).detach().cpu()” to put embedding to CPU rather than GPU. Thus the problem solved. But then there comes a new worry for me: Under this circumstance, the CPU utility and GPU utility are very high, nearly 100%. I think that there are still some ways to optimize the training process. I will do some reseaches concerning it later. And there are still something to mention: we use net.eval() and torch.no_grad() to reduce the computation. The difference between the two are that net.eval() will change the operation of network, for example stop Dropout and BatchNorm. And torch.no_grad() will ban the calculation of gradient. Both of the two ways can decrease the complexity of computation. We usually use them at the same time, guarantee correctness and computation efficiency.
Unluckily, the result of this is even worse than our previous trained without online triplet mining.
ideas:
1.Siamese network
2.Triplet loss(Online triplet mining)
3.Cosine annealing
4.T-SNE
5.lightweight network
Todo:
1.Add a funtion that draw loss curve during the training process
2.Check the reason why use mobile net all the output from the net will be nan
We have found out the reason for why the trained mobile net output all nan. The cause for this problem is that we trained our model on cuda, since the dataset market1501 are not so big, we can load it in GPU before training to accerlate training process, but this will increase time cost and make the output of net become all 0. I do not know the reason for this. But I solve the problem, just do not put dataset to GPU before training is ok.
And we draw the loss curve during the training process, the result can be seen as below: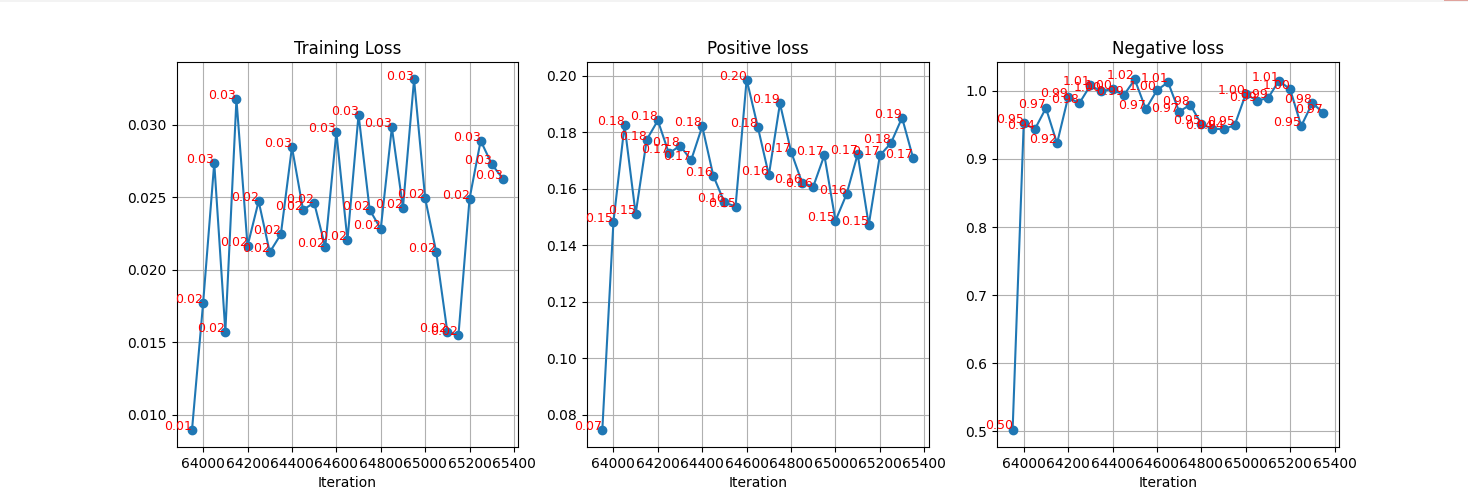
There are two points that confused me a lot: one is that why the first point of the curve is apparently smaller than the others, and the other is that why the positive loss is still so “big”. I expect the positive loss be smaller than 0.1. I think the reason for the positive loss is the value of margin, maybe it can be small if we set the margin to a greater number.
And there are still one problem when we draw loss curve during the training process, the first point of the curve of each epoch is relatively small than the other points, regardless of the training loss, positive loss and negative loss. The result for this is that the first point of each point is the last point of last epoch according to our code. So it will cause problem. We can reset our points at each epoch and this result will be solved.
At the same time, we do some adjustment to the Market1501 dataset.(Data cleaning). We find that there are many noises in Market1501 dataset, for some person in image are so small, some image has one or more person, some person is hidden in image and so on. So since our work are based on yolov5, so we first detect the person in each image of Market1501 with yolov5 and then choose the right person in each class manually to clean the dataset. After the data clean, in each training epoch we have 1120 sets. And we have 1540 sets in original dataset. After the data cleaning and pervious efforts, I have no idea of how can I imporve my network. We trained the network with different margin in triplet loss, from 0.3 to 0.9.
To find out the optimal value of margin, we first need to analysis the meaning and the usage of margin. The goal of neural network is minizing “loss”, in other words, optimizing loss to 0. In common sense, we regrad loss greater than 0 defaultly. But in some cases, the loss if we defined not so well, the loss can be negative. So if the loss is negative, the neural network goal is to pushing it to 0,i.e. making it bigger than previous. Thus, we should design our loss so that it can never smaller than 0 and at the same time conform to our optimization goal. And this is where margin makes difference. To one point, margin is the constant we added to the positive minus negative distance to make sure that the loss is greater than 0. To the other point, margin is the min numerical difference between positive distance and negative distance. So if we set the margin too big, the “remained” distance space for positive distance and negative distance are small, meaning that the distance we calculated has more errors. For example, for the distance we defined: 1 - cosine_similarity, so the distance is between 0 and 2. If we set margin to 1.5, then when the neural network learn, there are only 1 - margin = 0.5 distance space for positive space and negative distance respectively. Thus the error rate is high for we can not distingish different class in such a small space. But if we set margin too small, for example 0.5. Thus the min distance between for positive distance and negative distance is small. The setting of different threshold will be hard. For instance, if we set margin to 0.5. And thus after the learning process, we expect the network to has the ability for all the same class images’ distance are small and all the between class images’ distance are big, and their distance difference is 0.5. Suppose that the positive distance is usually smaller than 0.1, then negative distance is bigger than 0.6. But when we use the network to distingish real people(In test stage), we will find that the between class distance can be any value. Thus making the margin hard to determine whether the two image belong to same person or not. After our test and many experiment, we find that for this problem, set margin between 0.7 and 0.9 is good. And there is still one problem concerning margin confuse me: during the training process, we set margin to 0.7 and 0.9, we find that no matter what value we set to margin, the network learned the positive distance is about 0.1 and the negative distance is about 1.0, fluctuate about these two values.