LLM load and inference
大模型载入及推理细节:
首先是大模型载入:
代码:
这里载入的模型结构如下: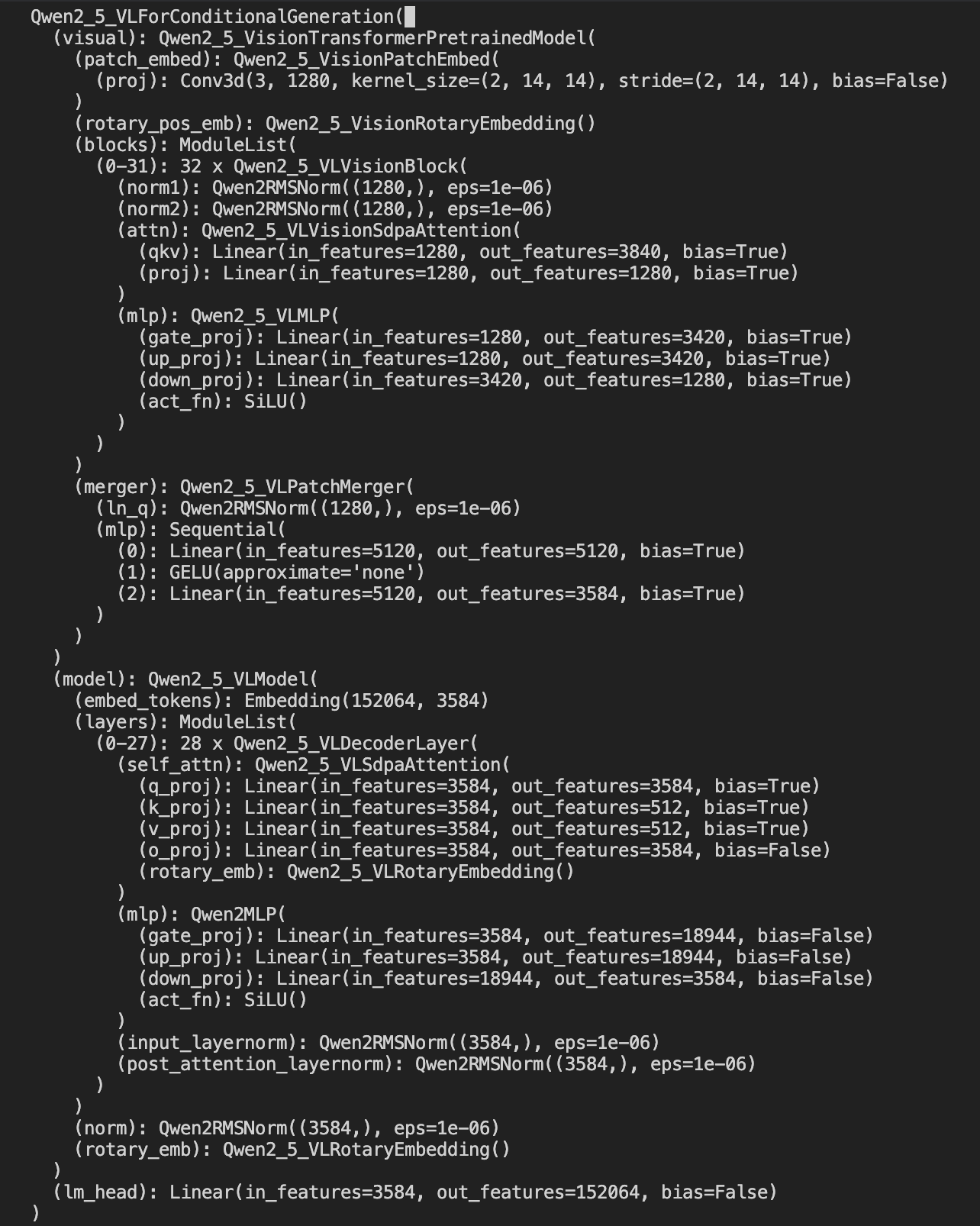
载入过程具体代码:
这里进入断点之后会进入一系列函数:
这里我们一个一个看,首先是
patcher.py 285行:
这里会得到model的本地路径,之后代码从这个路径中来读取模型的信息
modeling_utils.py 279行:
这里就是进一步调用载入模型的函数,在279行点击单步调试之后会进入到modeling_utils.py的3959行,这里从3959到4399行全都是大模型载入过程中一些超参数的设置,比如模型参数保留的浮点位数,模型参数存储的文件格式等等。这里有一个比较关键的点是metadata。
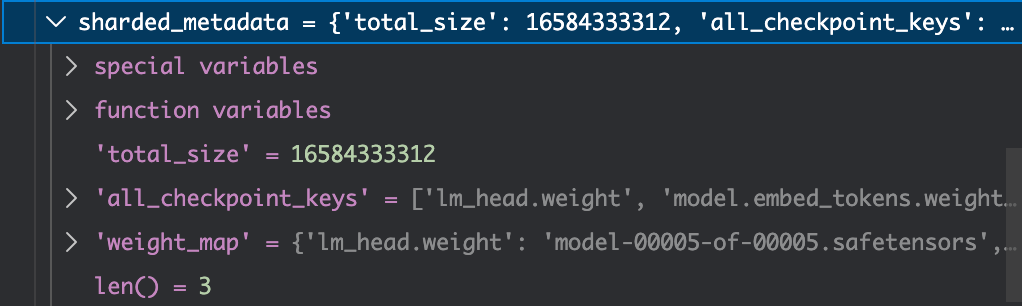
metadata是从权重safetensor文件中读取的模型相关参数,比如结构,hidden_size等
也就是说,在这里代码就已经载入了模型的结构,之后是模型权重的载入。
modeling_utils.py的4399行进入_load_pretrained_model,在_load_pretrained_model函数中,这里首先从sharded_metadata中读取了模型结构以及每一层的名称:
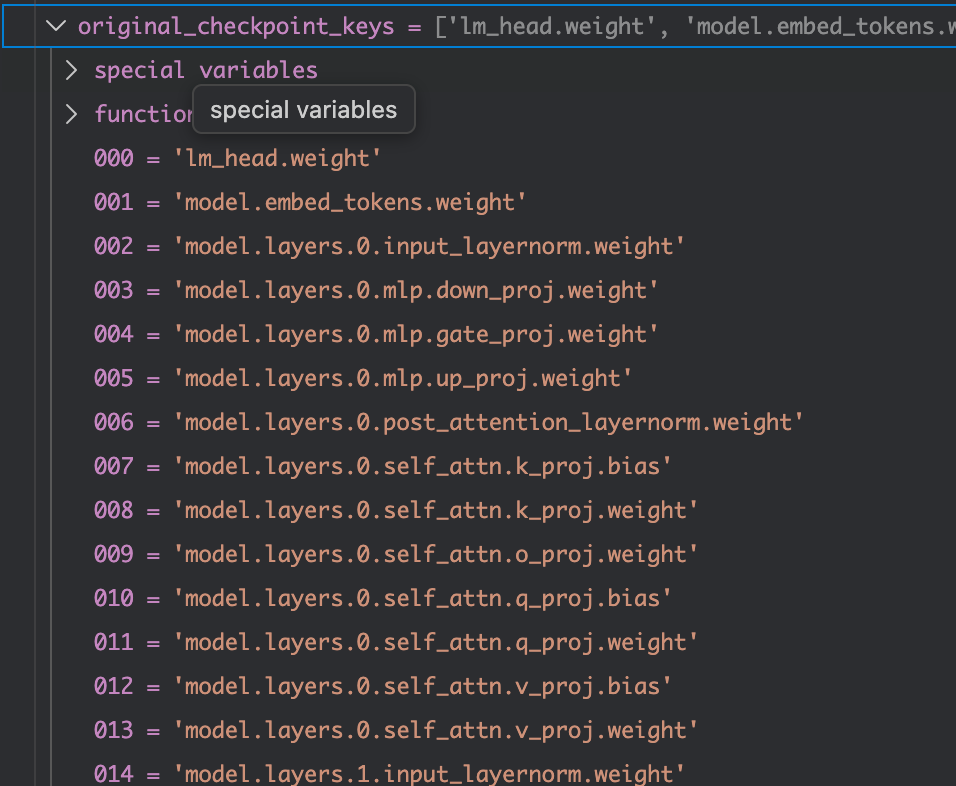
之后该函数直到4796行都是一些异常情况处理,因为这里我们载入的模型结构是从safetensor中加载的,不一定和我们config中的模型结构的权重一样,所以这里代码中进行了safetensor中多了以及少了的参数(正常情况下二者全都是空)。这里做一个解释,下载下来模型文件夹中有几个关键的模型结构的文件:config.json, xxxx-xxxx.safetensor,model.safetensors.index.json这些文件,对于这里,config.json是这样的: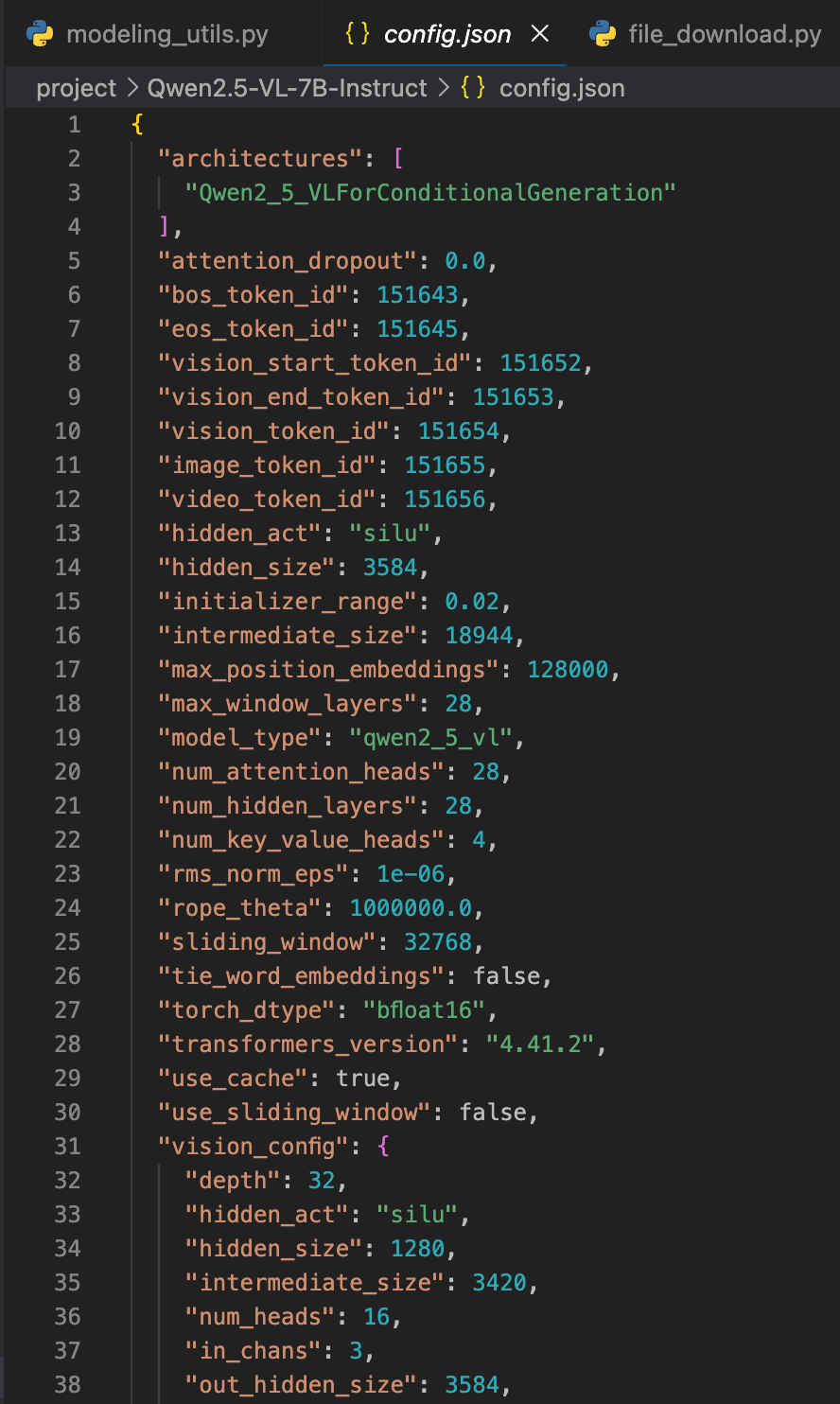
这里”architecture”决定了模型的结构,之后其他的参数用来决定具体的(比如这里决定是7B还是32B)。
同时model.safetensors.index.json,这个文件包含了一个weight_map,weight_map中决定了模型中每一层的参数到底在那个safetensor文件中。所以说这里可能会产生模型结构的不一致:config.json中定义的模型结构的名称和weight_map中的模型结构名称不同甚至模型结构不同,所以这里需要进行一些检查。
之后便是: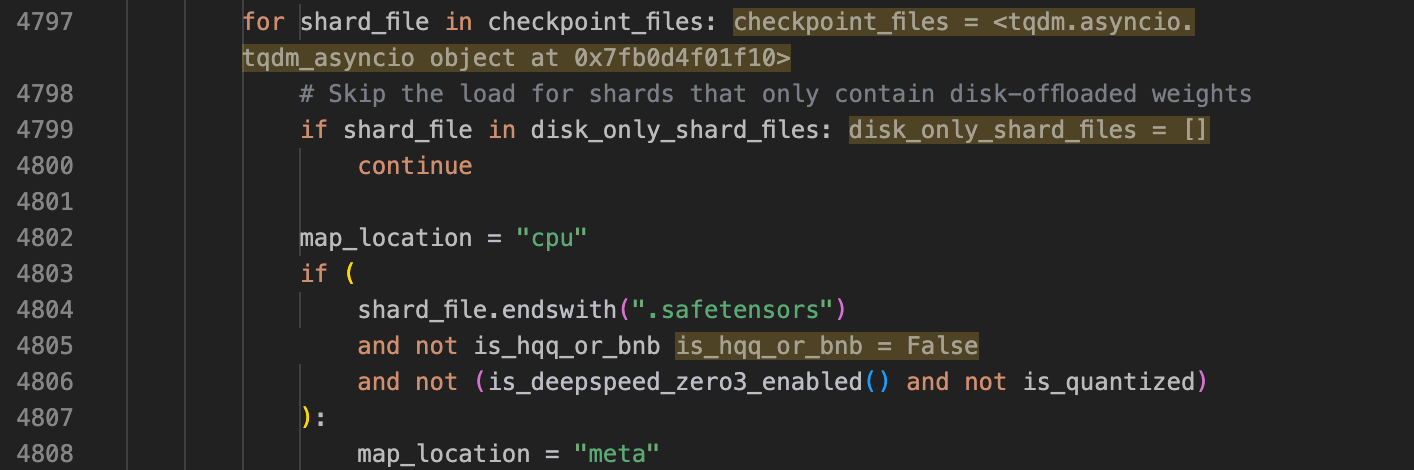
这里通过代码可以发现,这里的map_location是meta,但是这里我是用的是L40s的计算卡,在代码最一开始加载的时候我已经指定了torch.device为GPU,但是这里载入的时候在代码中可以发现模型是先载入到torch.device为meta的设备中,这是因为这里模型权重是分片存储的,也就是说不是一个safetensor文件就可以放得下。meta是一种“虚拟设备”,参数张量是 meta tensor,这样的tensor只有 shape/dtype,没有真正的数据存储,这种情况下构建模型很省内存,但不能用来推理/训练。这样可以避免OOM以及可以支持分片存储权重的读取。这里查看具体的device为meta的数据:
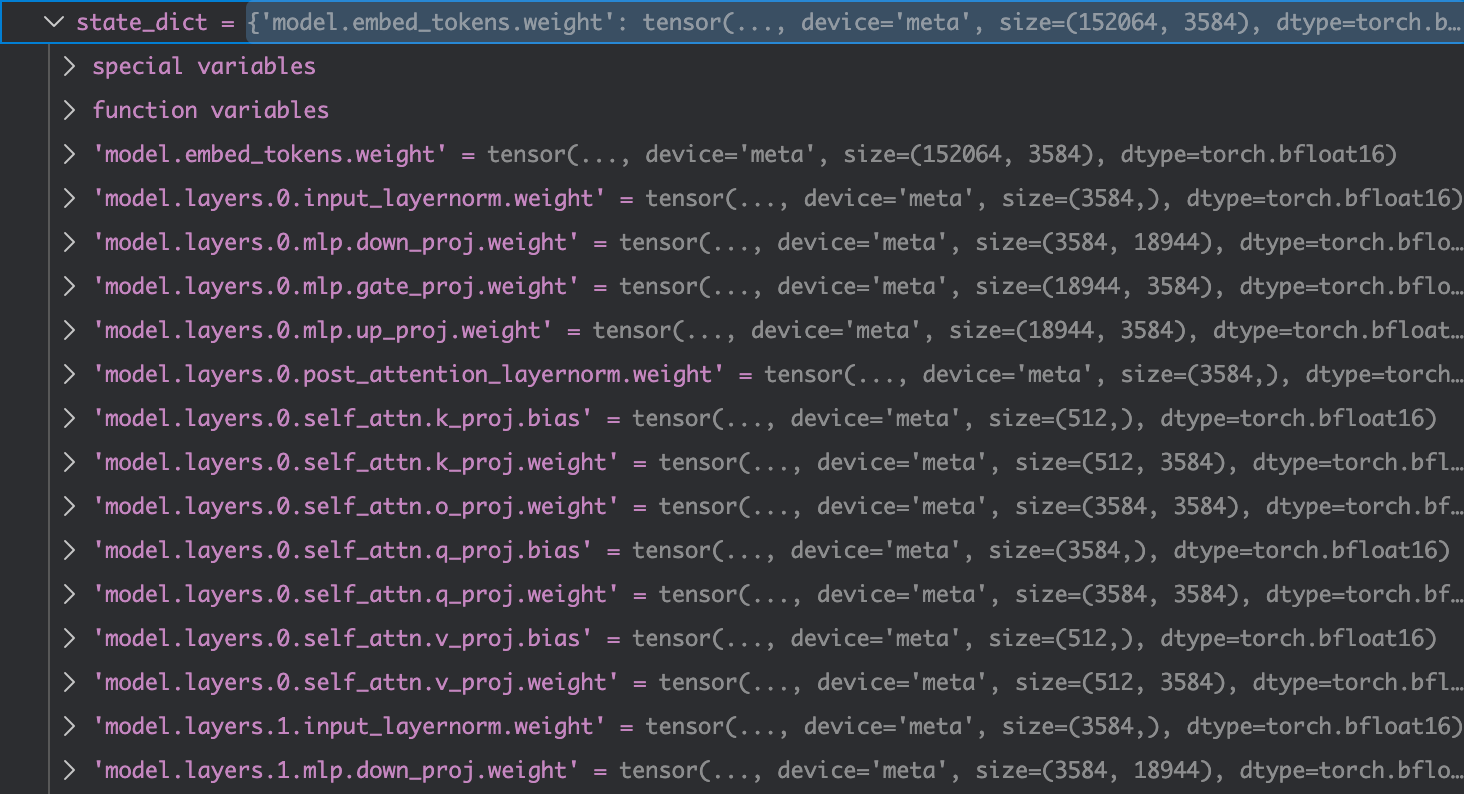
这里由于只载入了第一个safetensor中的权重,所以与之前的original_checkpoint_keys有一些区别。
之后在4833行可以很明显的看到_load_state_dict_into_meta_model是把真实的模型权重加载到刚刚载入的meta模型中,这里从_load_state_dict_into_meta_model模型的device_map可以看到,是要载入到GPU中。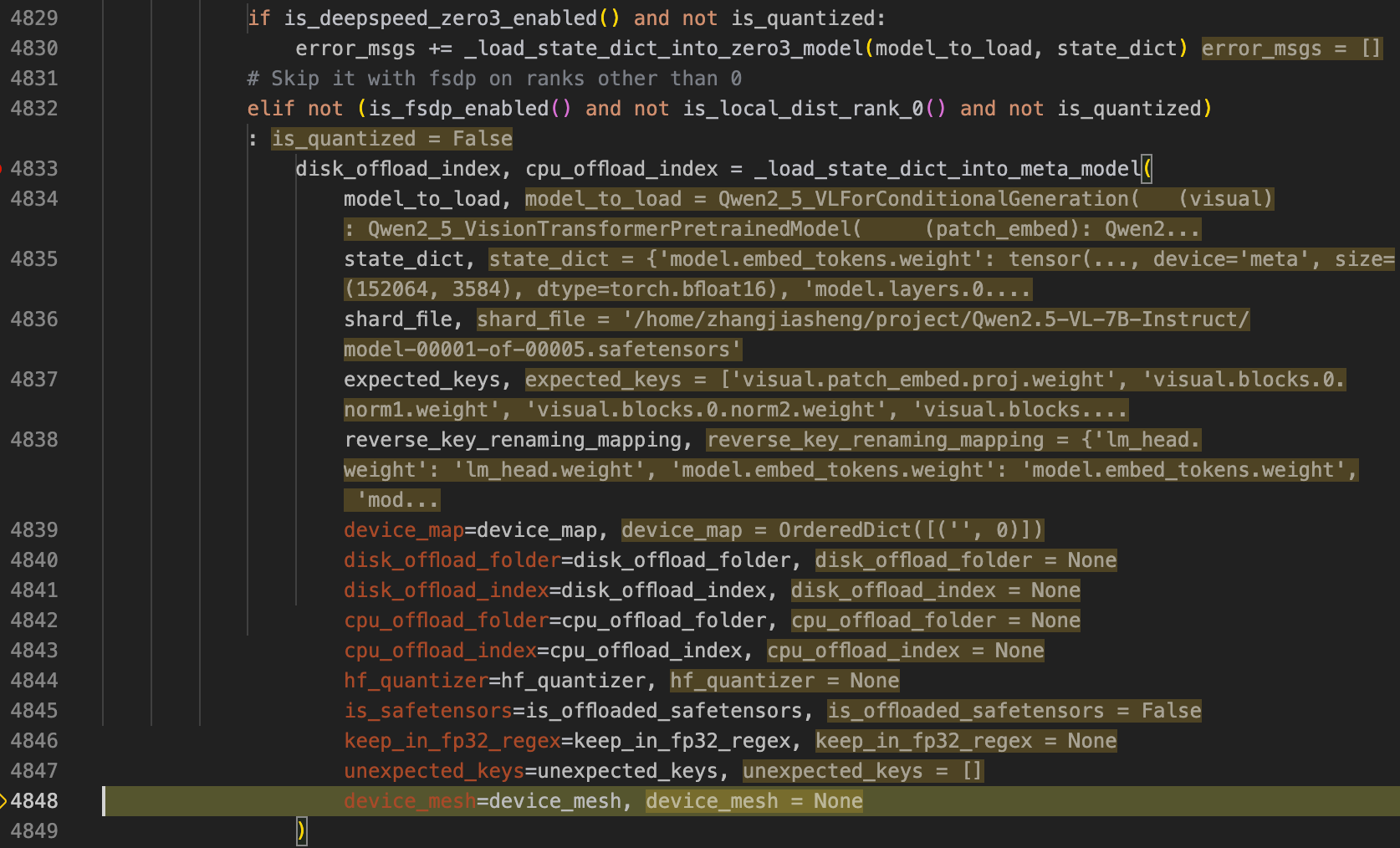
之后便到了_load_state_dict_into_meta_model这个函数,这个函数会把每一个参数都从safetensor文件中读取出来: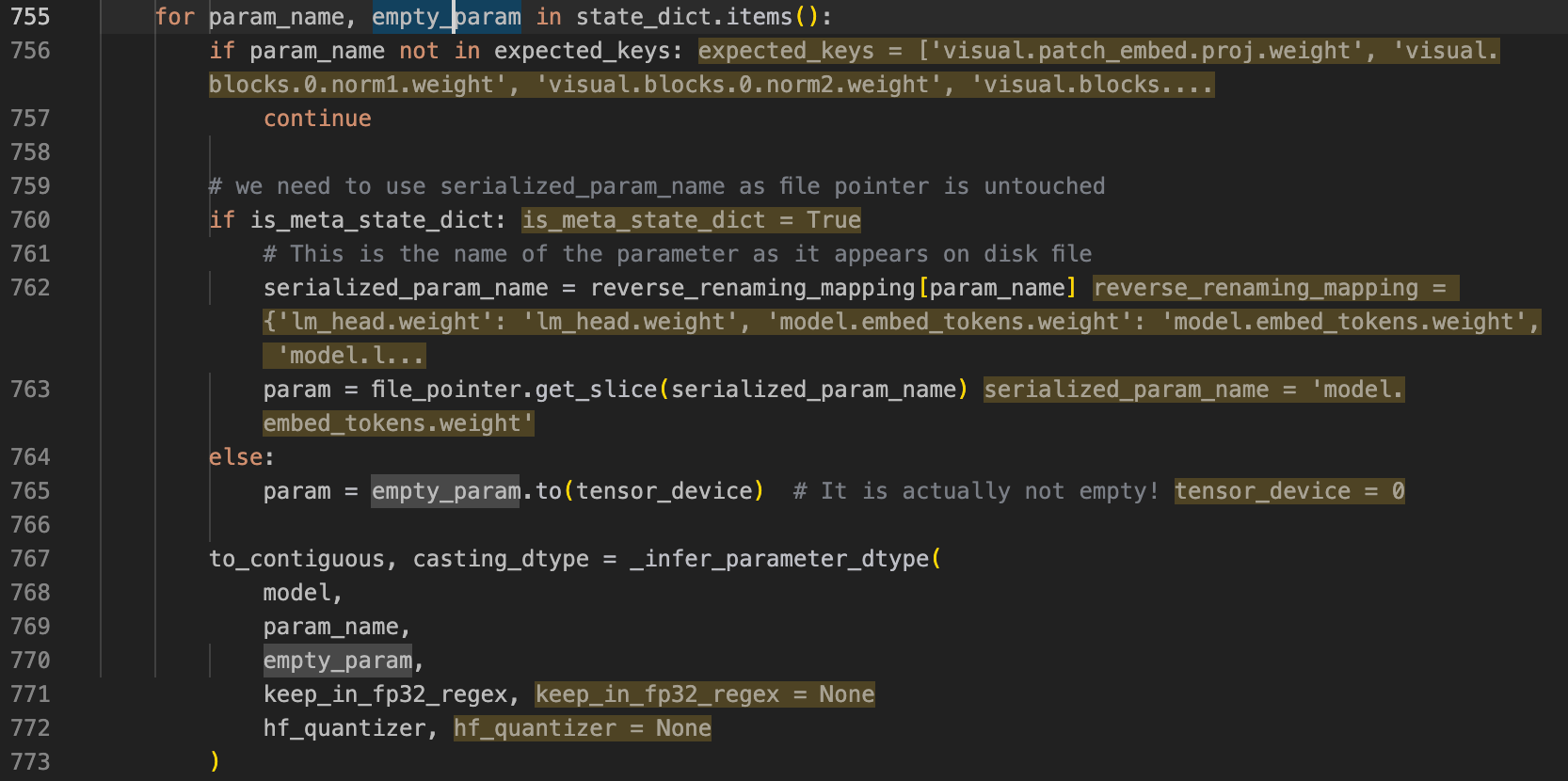
这里for 循环是读每一个参数,之后的763行是得到这个参数具体的权重值,这里进行验证:
这里的param_name是model_embed_tokens.weight
这里可以看到empty_param也就是之前load到meta设备中的大小,它的size和param.shape的size一样,证明没问题。这样一直循环,便可以得到模型的所有权重。
大模型推理具体代码: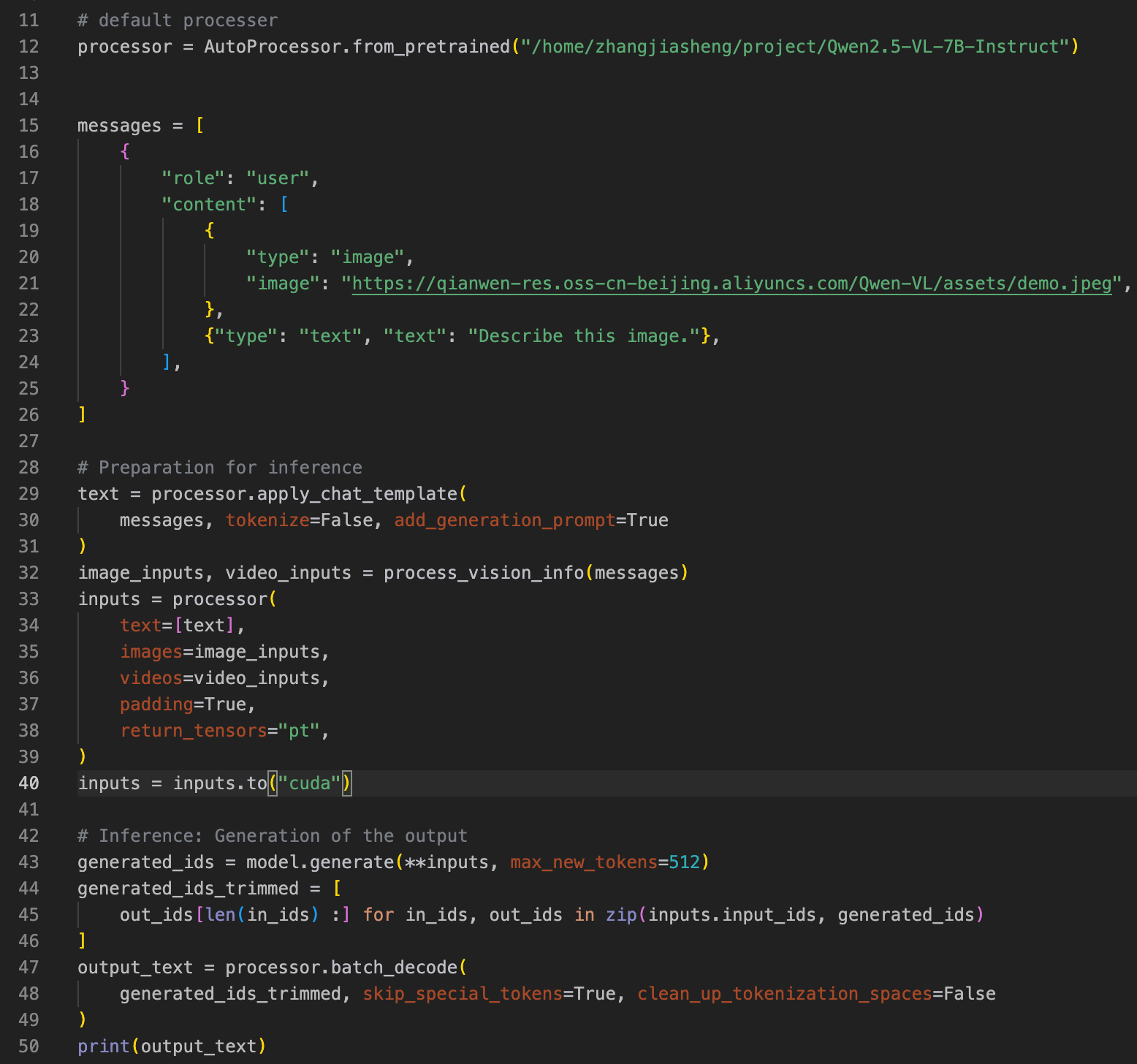
这里首先从模型载入到模型推理还需要几个处理,这是因为 model 只负责“吃张量、吐结果”,而 Qwen2.5-VL 这类多模态模型在喂给模型之前,需要把「文本 + 图片/视频」统一加工成模型需要的那套输入张量(不仅仅是 input_ids)。这件事就是 processor(AutoProcessor)在做。
首先processor先处理text,这里我的理解就是把用户的需求(用户输入的prompt)加入一些特殊的token,比如这里的im_start, vision_start等等,这样大模型可以更好的处理这种多模态输入。
之后是通过process_vision_info()函数,从message中提取出来视觉输出的部分,把图片/视频的链接变成可处理的视觉输入对象,这里变成了一个PIL.Image:
之后是使用先前定义的processor,把文本输入和视觉输入打包成一个张量(这里并没有经过复杂的神经网络,对文本模态,进行分词等工作;对于视觉模态,resize / normalize / 切 patch 等 操作变成pixel_values):
经过processor之后: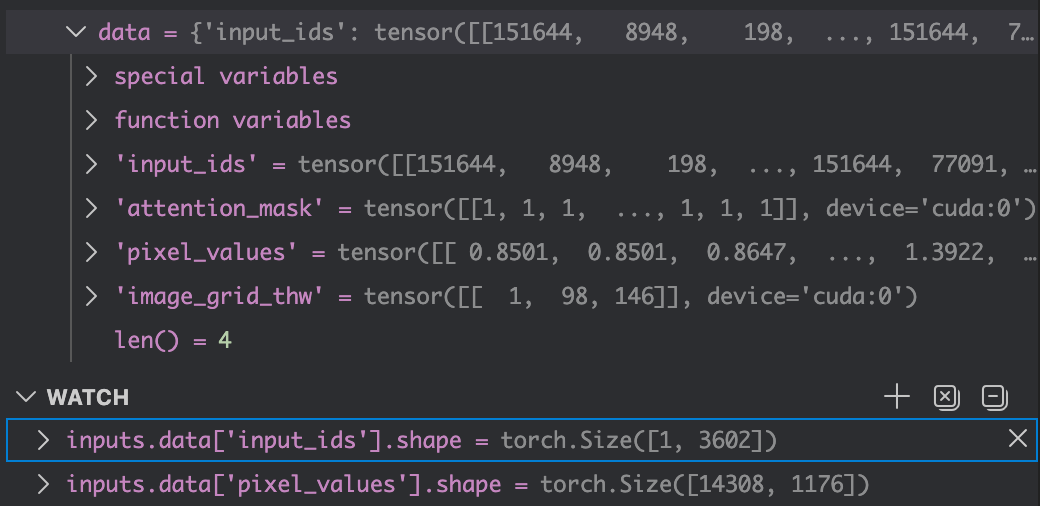
这里这样写更加清晰:这里的inputs.data包含了我这里inputs的大部分关键数据,这里我们可以看到inputs.data[‘input_ids’].shape为[1,3602],1代表了batch_size是1,这里的3602是 文本 token +(视觉占位 token)+(一些特殊 token)的长度。这里由于视觉编码器的权重这里还没有利用过,所以这里inputs.data中有一项为pixel_values,这一项用来保存视觉输入的像素。
之后才会经过模型进行generate。
generate的具体过程是这样的:
首先是进入到了utils.py的2113行:generate()函数中,在函数中会进行一系列generate过程中需要的参数的初始化。在2306行会生成一个generation_config.max_length。这里这个参数的值为我们之前输入的3602+我们在生成时给出的max_new_tokens(512),所以这里就是4114,因为LLM推理过程其实是一个续写的过程,我们给出的prompt和视觉模态全都是给了LLM一个前提,LLM通过这个前提来续写,所以这里需要将二者加起来,这样才可以进行正确的注意力掩码。之后便会准备cache,generation mode(这里是sample),以及 logits processors and stopping criteria。这里的logits processor的意义是在 generate() 逐步生成时,每一步模型输出“下一 token 的原始 logits”(还没 softmax)之后,先对这些 logits 做一轮规则处理/约束/惩罚,再去采样或取 argmax,让生成满足某些策略或硬约束。
之后,在2465行进入sample:
这里进入_sample函数:
这里首先会定义一系列参数:
之后会在3422行开始循环,一个一个token进行forward:
这里while第一次循环(prefill:在自回归生成里,第一次把整段 prompt一次性喂给模型,把 KV cache “填满/预热” )会走3430这一行的条件,之后会进入modeling_qwen2_5_vl.py的1756forward函数: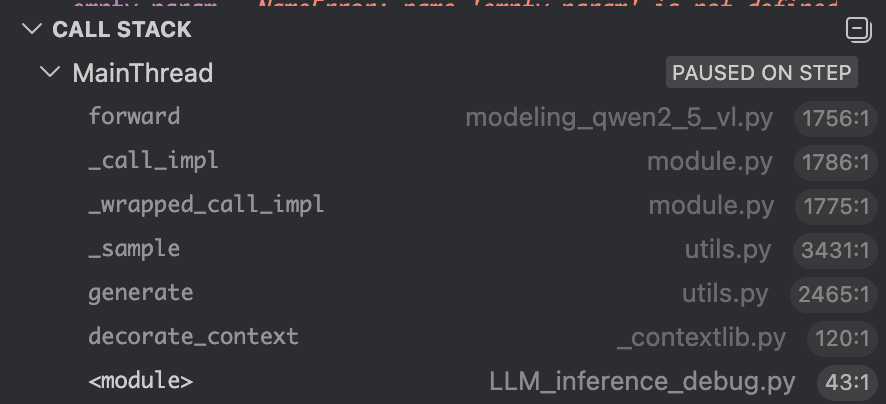
forward函数是这样的: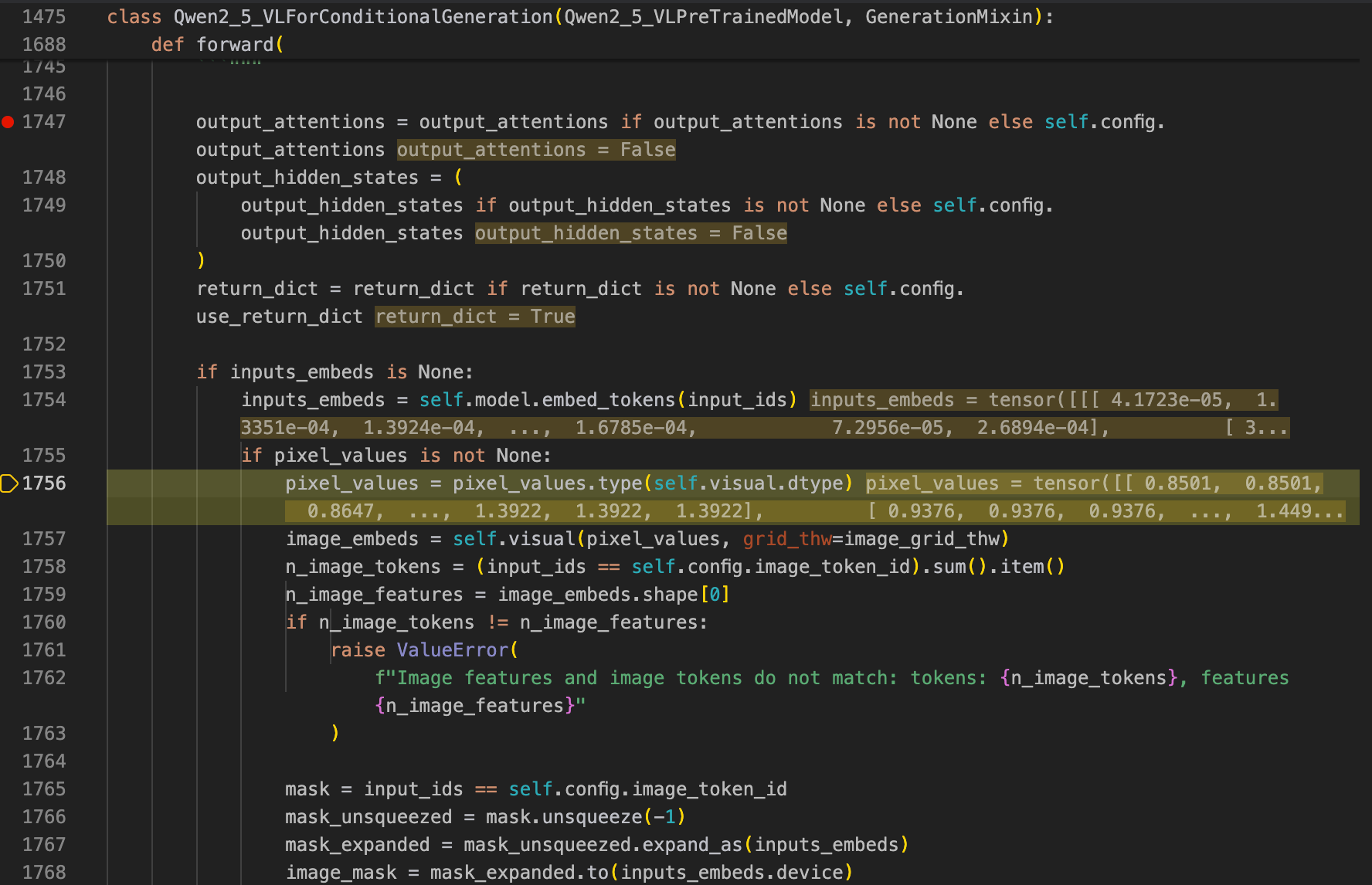
inputs_embeds是这里对3602个之前inputs_ids embedding之后的结果。这里调试发现,总共3602个token中有3577个是image的token,之后的代码会将这3602个tokens中的这3577个embedings之前的视觉占位符替换为这里的刚刚得到的image_embeds: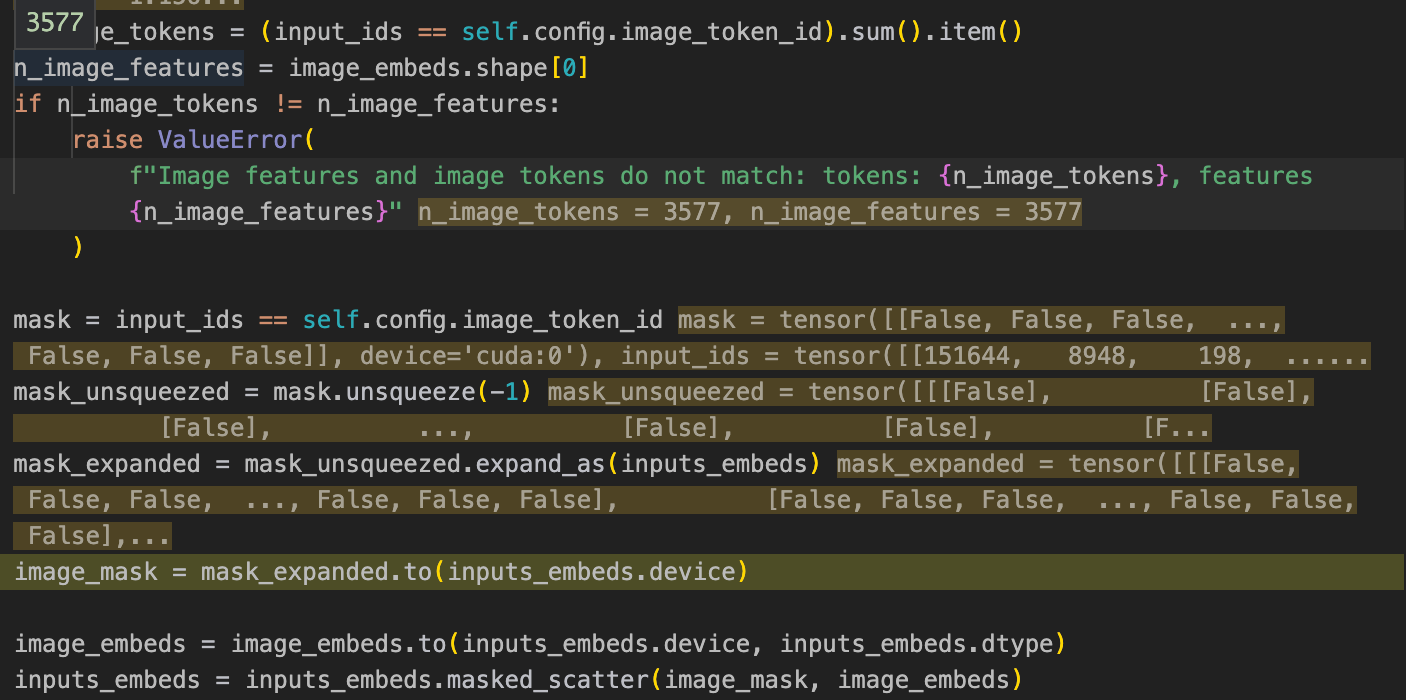
之后在1795行,我们计算RoPE,给这里我们得到的embeddings加入位置编码,这里由于RoPE的性质,我们只需要在pre-fill阶段算一次RoPE即可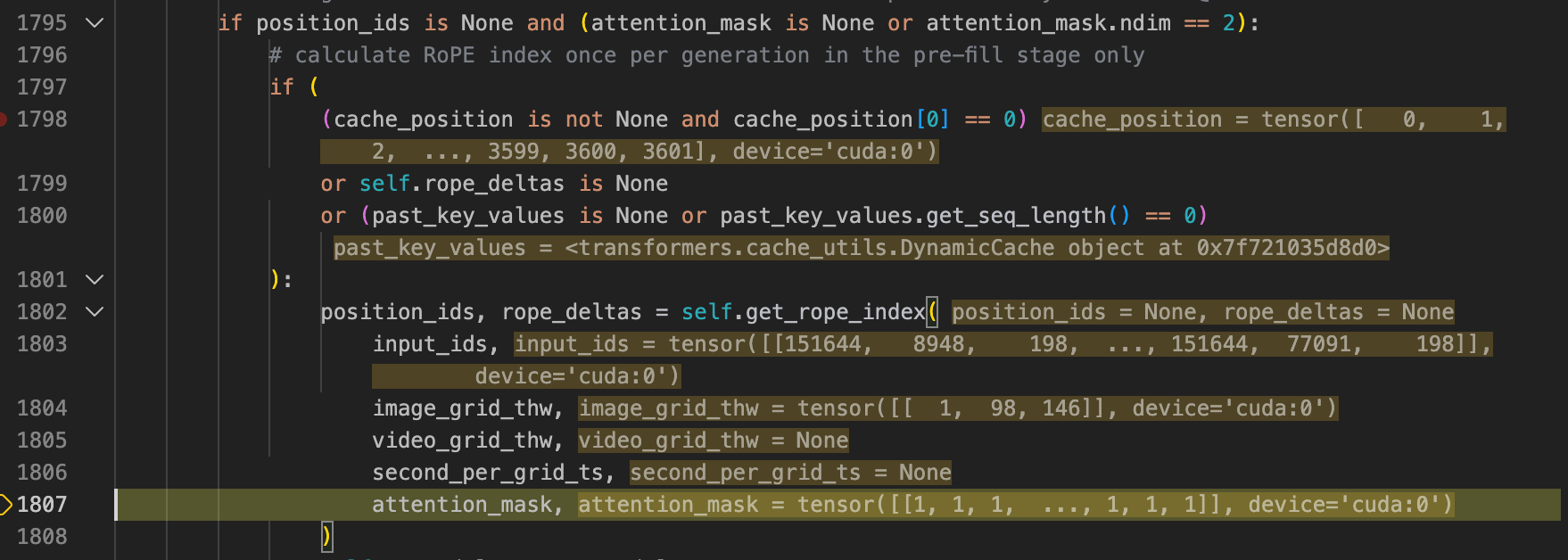
之后在1825来进行模型的推理: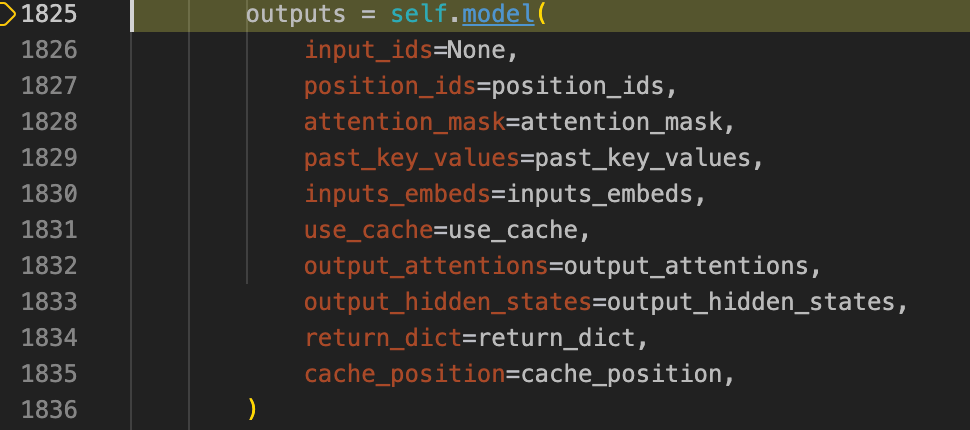
进入这里的self.model,这里call stack变成了这样: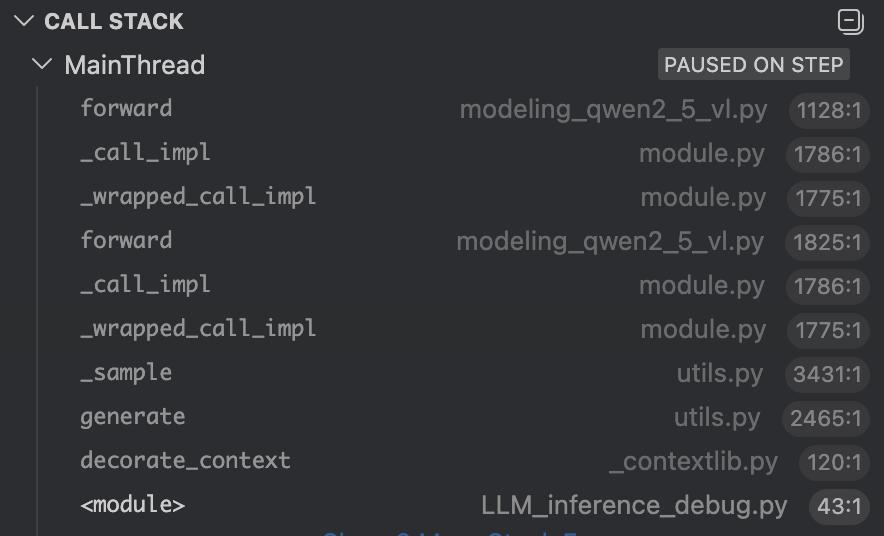
这里和上一步相比,多了一个forward和_call_impl,这里的新的forward是在class Qwen2_5_VL_Model下的,之前的那个forward是在Qwen2_5_VLForConditionalGeneration下的,二者有所不同。
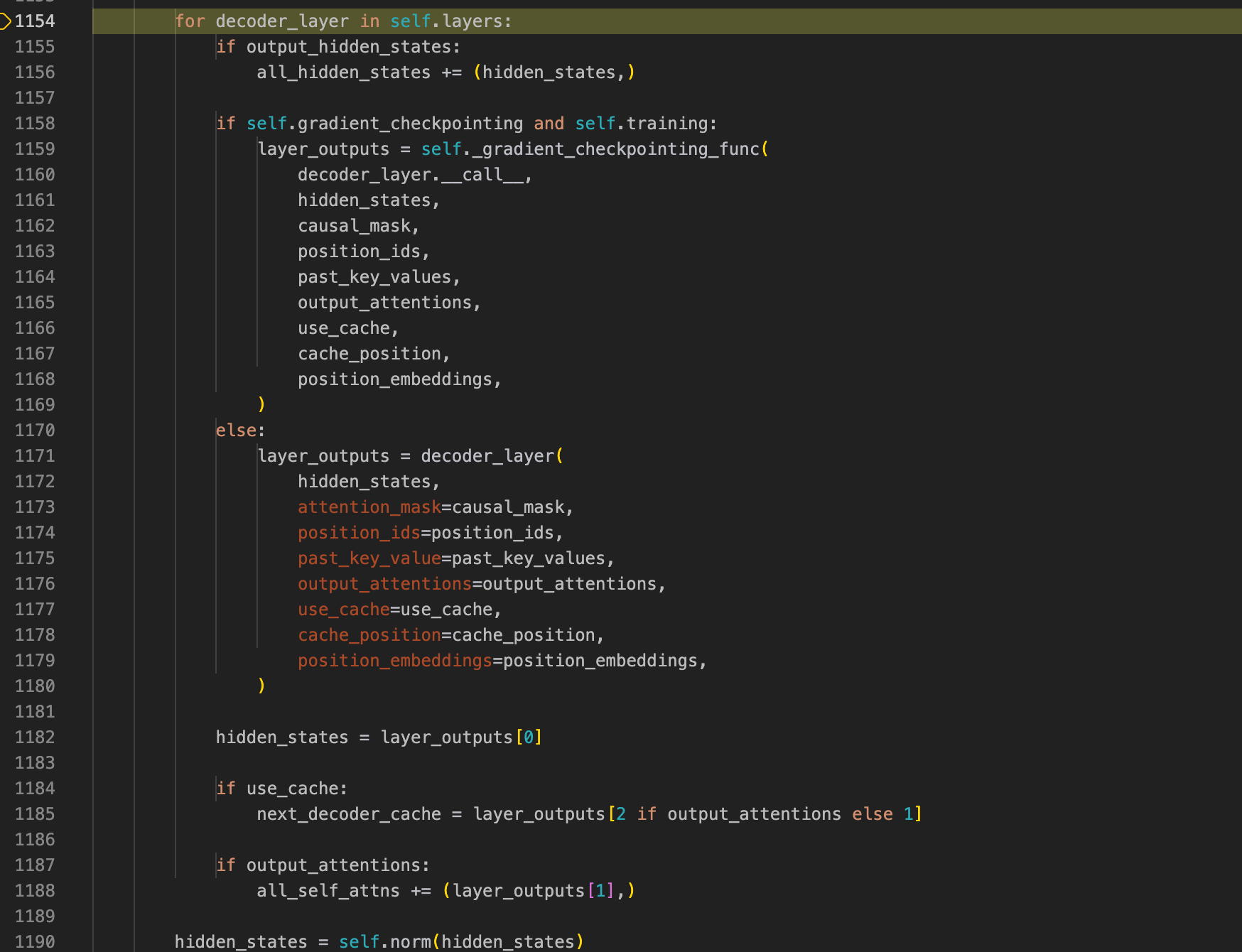
在这里的forward,我们就可以看到模型经过模型所有的decoder_layer来进行推理,之后便是decoder层结束之后的norm:
:
最后是一些cache的处理:
这个是一个检查函数,检查是否出错的函数。
这里经过每生成一个token都会经过一个forward过程,直到生成数量达到max_new_token或者生成了EOS结束生成的token。